Multi-Agent-System aufbauen: Wie ein Solo-Berater sein eigenes KI-System gebaut hat (Teil 1)
- Marcus Machon

- 21. Apr.
- 31 Min. Lesezeit
Aktualisiert: 29. Mai
Wer heute ein Multi-Agent-System aufbauen will, steht vor zwei Entscheidungen, die über Erfolg oder Frust entscheiden, und beide haben nichts mit Programmieren zu tun. Die erste: das Modell. Ich habe in zwei Monaten gelernt, dass man hier nicht sparen darf. Viele Dinge, die heute sauber laufen, liefen bei mir erst ab Claude Opus 4.6 überhaupt. Und die Modelle werden monatlich besser; Anthropic beschreibt Opus 4.7 als deutliche Verbesserung für Coding, Agenten und lang laufende Aufgaben. Die zweite Entscheidung: die Architektur. Viele Anläufe scheitern nicht am Modell, sondern an der Einstiegs-Ebene und an fehlender Struktur. Genau darum geht es in diesem ersten Teil. Teil 2 ist inzwischen online und behandelt die Schwächen, Fehler und Risiken.
Wenn Sie ein KI-Agenten-System aufbauen oder echte Multi-Agent-System Erfahrungen suchen, bekommen Sie hier keine Blaupause zum Nachklicken, sondern einen Werkstattbericht: Was hat funktioniert, was war zu kompliziert, wo hat mir ein Claude Code Multi-Agent-System geholfen und wo musste ich als Mensch wieder selbst entscheiden? Für ein KI-System im Mittelstand ist genau diese Unterscheidung wichtiger als die Frage, wie viele Agenten im Diagramm stehen. Und wenn Sie selbst ein Multi-Agent-System aufbauen möchten, ist die wichtigste Frage nicht "welches Framework?", sondern "welcher Kontext darf zuverlässig ins System?"
Einen Anspruch habe ich nicht: dass meine Lösung für Ihr Unternehmen passt. Mein System ist ein persönliches Experiment auf einem alten Linux-Rechner, ohne kritische Daten, mit öffentlichen Studien und meiner eigenen Arbeit als Datenbasis. Keine Enterprise-Umgebung, keine Regulatorik, keine Kundendaten. Dafür aber rund zwei Monate echte Praxis (Start: 20. Februar 2026), und ein paar Zahlen, die größer geworden sind, als ich selbst für möglich hielt:
über 110 Fach-Tabellen in einer zentralen Datenbank mit über 130.000 Datensätzen (inklusive Audit-Log, Wissens-Index und semantischer Chunks)
über 2.400 vernetzte Markdown-Dokumente als Wissensbasis
über 40 nächtliche Automatisierungen
23 wiederverwendbare Arbeitsabläufe (Skills) und fünf spezialisierte Sub-Agenten
über 2.000 Messungen der Skill-Qualität
rund 400 dokumentierte Fehlermuster, derselbe Fehler passiert heute deutlich seltener (ehrlich: ganz verschwunden ist er nicht)
und: seit Inbetriebnahme kein einziger kritischer Systemfehler
Die letzte Zahl ist mir die wichtigste. Kein Datenverlust, kein produktionsrelevanter Ausfall, keine falschen Zahlen in Veröffentlichungen. Dass das System täglich weiterwächst, macht das nicht selbstverständlich.
Die Landkarte: Layer, Domänen und CCCs
Wenn Sie nur eine Struktur-Idee aus diesem Beitrag mitnehmen, dann diese: Mein System ist eine Landkarte aus drei Koordinaten, nicht nur eine Sammlung einzelner Automatisierungen.
Kurz gesagt: Layer erklären, auf welcher Ebene Arbeit passiert. Domänen erklären, in welchem Geschäftsbereich sie passiert. CCCs, also Cross-Cutting Concerns, erklären, welche Prüfbrille immer mitlaufen muss.
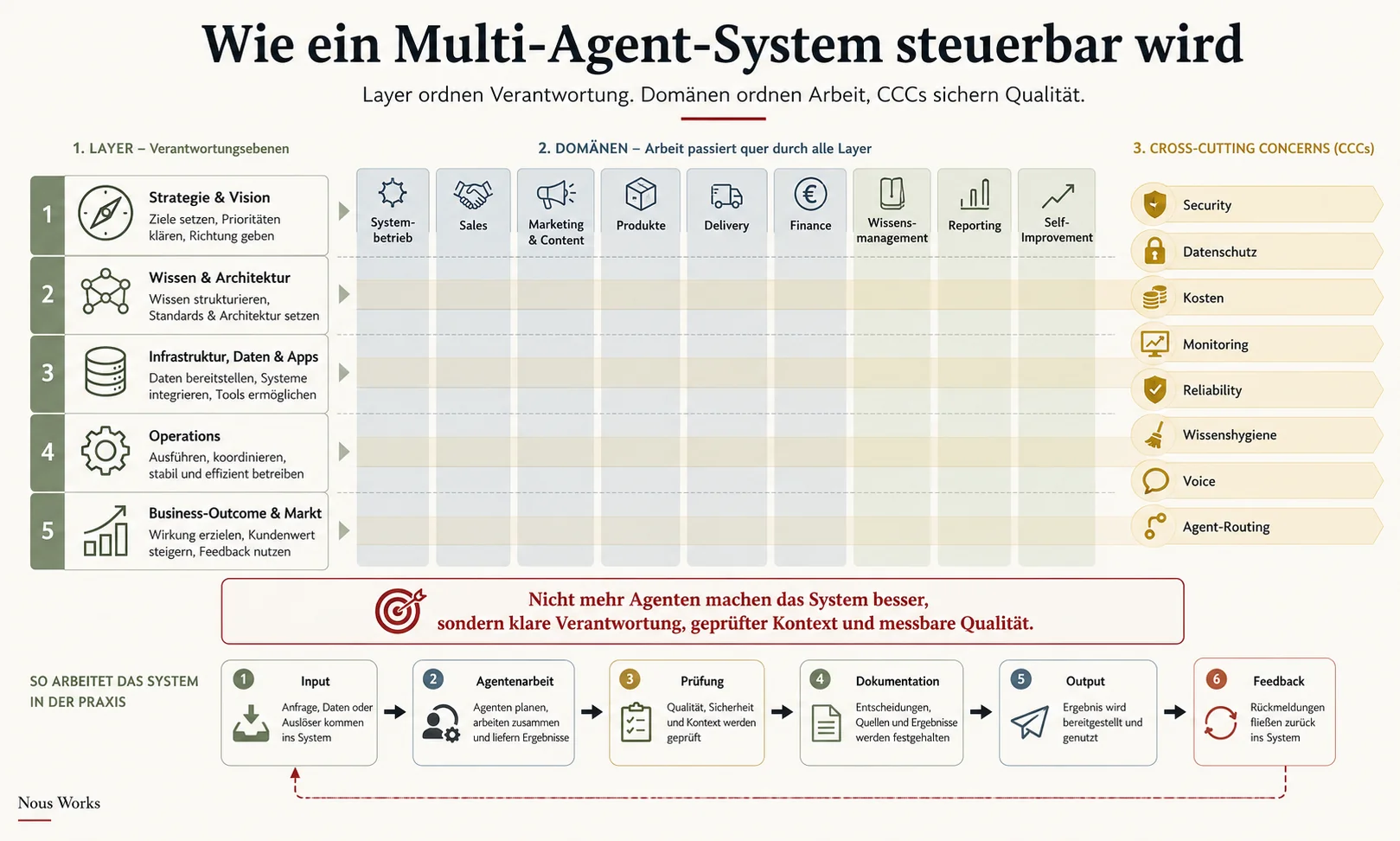
Die fünf Layer verlaufen von oben nach unten: Strategie und Vision, Wissen und Architektur, Infrastruktur mit Daten und Apps, Operations, Business-Outcome und Markt. Das verhindert, dass ein Agent nur fleißig arbeitet, ohne auf ein Ziel einzuzahlen. Wenn ein Blogpost entsteht, ist das Layer 4. Wenn er keine Resonanz erzeugt, ist das ein Signal aus Layer 5 zurück an Strategie und Architektur.
Die neun Domänen schneiden horizontal durch diese Layer: Systembetrieb, Sales, Marketing und Content, Produkte, Delivery, Finance, Wissensmanagement, Reporting und Self-Improvement. Dadurch kann ich sehr konkret sagen: Diese Änderung betrifft nicht "das System", sondern zum Beispiel Content, Wissensmanagement und Reporting gleichzeitig.
Die CCCs sind die Themen, die überall mitlaufen müssen: Security, Datenschutz, Kosten, Observability, Reliability, Wissenshygiene, Voice und Agent-Routing. Das klingt trocken, ist aber der Unterschied zwischen einem Spielzeug und einem System, das man länger betreiben kann. Security ist zum Beispiel keine eigene Schublade. Sie liegt über allen Layern und jeder Domäne.
Was dieser Beitrag ist, und warum er umsonst ist
Ich lege hier mein komplettes Vorgehen offen: Architektur, Fehler, Quellen und die Methode dahinter. Kostenlos, ohne Newsletter-Hürde, ohne Kurs-Funnel. Wer meine Zeit im Beratungs-Format will, bucht sie. Wer selbst bauen will, findet hier genug.
Mein Ansatz ist bewusst fast wissenschaftlich: gegengeprüfte Quellen, Entscheidungen schriftlich festgehalten, strittige Thesen nach einem festen Schema analysiert (Behauptung, Beleg, Konfidenz, Gegenposition). Gleichzeitig gehört zur Ehrlichkeit dazu, dass Arbeiten mit KI weird ist. Sie erfordert eine andere Denk- und Arbeitsweise, als ich sie aus zwanzig Jahren IT und Beratung kenne. Niemand in diesem Feld kann alles im Detail kennen. Die Modelle und Werkzeuge ändern sich im Monatsrhythmus, und wer klassisch an so ein KI-System rangeht, der Business Case, dann die Architekturkommission, dann ein dreimonatiges Pilotprojekt, scheitert meiner Überzeugung nach.
Was für mich funktioniert, ist ein kontinuierliches Abwägen zwischen zwei Polen. Auf der einen Seite: maximale Autonomie für die KI, inklusive Selbstverbesserung. In meiner Sandbox darf Claude fast alles. Code schreiben, Schema migrieren, Skills bauen, eigene Ergebnisse bewerten. Auf der anderen Seite: null Zugriff auf sensible Daten oder Tools, die ich nicht selbst durchblicke. Kein Kundendatenbestand, kein E-Mail-Versand ohne Freigabe, keine Produktionssysteme. Erst durch diese Kombination bin ich in der Lage, Dinge zu lösen, von denen ich vorher nicht einmal geträumt habe. Wer die KI im goldenen Käfig hält, bekommt Tool-Gefühl. Wer sie überall hinlässt, bekommt eine Katastrophe. Der Korridor dazwischen ist schmal, und er verändert sich mit jedem Modell-Release.
Aus dieser Mischung ist bei mir mit der Zeit ein Gefühl für mein System entstanden. Wo sind wahrscheinlich Lücken, wo verstecken sich Fehler, was fehlt. Das ist gleichzeitig eine Art Kunst: zu wissen, wann man messen muss, und wann Bauchgefühl reicht. Wer nur logisch-analytisch arbeitet, wird langsam. Wer nur vibe-codet, baut Chaos. Beides braucht es, in wechselnder Gewichtung.
Für alle, die selbst loslegen wollen, finden Sie an den entscheidenden Stellen Blöcke mit der Überschrift "Technisches Briefing für Ihr LLM". Diese Blöcke sind als Copy-Paste-Prompts gedacht: direkt in Ihre eigene Claude-, Gemini- oder ChatGPT-Instanz einfügen und recherchieren, erklären oder umsetzen lassen. Jede Box enthält Patterns, Fallstricke, Begründungen und, wo sinnvoll, konkrete Konfigurations-Hinweise. Das ist die Abkürzung, die ich selbst gerne gehabt hätte.
Sie finden einen Fehler? Eine bessere Quelle? Einen fehlenden Aspekt? Schreiben Sie mir direkt (Adresse am Ende). Ich aktualisiere diesen Beitrag aktiv, das ist der Vorteil eines Blogs gegenüber einem gedruckten Buch.
Warum das mehr ist als Hype: eine leise Disruption
Kritik an KI ist nicht falsch, sie hinkt nur oft dem Stand der Technik hinterher. Viele skeptische Studien stammen aus 2024 oder früher, als die Modelle schlicht nicht gut genug waren. Auch manche Studien aus 2025 arbeiten bereits mit Modellversionen, die heute nicht mehr den aktuellen Stand abbilden. Ende 2025 gab es einen Sprung, den ich im Alltag spüre: Aufgaben, an denen Modelle vor einem Jahr noch gescheitert sind, erledigt Claude heute in Minuten. Ein illustratives Beispiel aus dem Frühjahr 2026: Das Forschungssystem Claude Mythos Preview fand laut Anthropic Red Team, 2026 in FFmpeg eine 16 Jahre alte Sicherheitslücke und in OpenBSD sogar eine 27 Jahre alte, die jahrzehntelangen automatisierten und manuellen Prüfungen entgangen waren. Das ersetzt keine eigene Sicherheitsbewertung, zeigt aber, dass wir über andere Fähigkeiten reden als noch vor einem Jahr. Meinen eigenen "Hier passiert etwas Fundamentales"-Moment habe ich damals in einem LinkedIn-Post festgehalten, bei dem viele dachten, ich übertreibe. Ich tat es nicht.
Die typischen Kritiken am sogenannten Vibe Coding (einfach die KI bauen lassen und hoffen) kann ich trotzdem nachvollziehen. Ja, die KI macht Fehler. Ja, Code bläht sich ohne Kontrolle auf. Ja, Abhängigkeiten wachsen im Stillen. Aber: Wer das System ernsthaft überwachen lässt, fängt diese Probleme früh ab. Bei mir läuft seit über zwei Monaten kein einziger kritischer Fehler. Jedes ernsthafte Problem habe ich bisher rechtzeitig gesehen und meist schnell gelöst. Bugfixing und Monitoring gehören zum Alltag, manchmal frisst das viel Zeit, vor allem weil ich Teile der Architektur teilweise wöchentlich umbaue. Aber ich sehe an Dashboards, Auswertungen und Prozessen sehr schnell, wenn etwas aus dem Ruder läuft. Blinde Flecken bleiben, wie überall. Der Punkt ist: Die Kritiken an KI-gestütztem Bauen haben einen wahren Kern. Mit einer bewusst gewählten Architektur, einem Fehler-Gedächtnis und dem Willen, hinzuschauen, sind sie meiner Erfahrung nach lösbar.
Drei Dinge sind heute fundamental anders:
Erstens: Das Eintrittsticket liegt im zweistelligen Bereich, nicht im hohen fünfstelligen. Ich zahle ein Monats-Abo für Claude und nutze einen alten Rechner. Eine KI-Schätzung für den Nachbau meines Systems durch eine Agentur lag bei rund 50.000 Euro und drei Personen, und die Zahl halte ich inzwischen für zu niedrig. Das ist kein belastbarer Marktpreis, aber die Größenordnung spricht für sich: Was gestern noch ein Projekt mit Budget, Lenkungskreis und Dienstleister war, wird heute zum Wochenend-Experiment eines Einzelnen.
Zweitens: Die großen Enterprise-Blocker greifen bei Solo-Operatoren und kleinen Teams nicht. Was Konzerne bremst (Governance, Altsysteme, Datenschutz) spielt für Einzelne mit öffentlichen Daten kaum eine Rolle, dazu gleich mehr. Die Disruption passiert deshalb an den Rändern: bei Beraterinnen, Freelancern, kleinen Fachfirmen. Die können heute in zwei Monaten haben, wofür Konzerne Jahre brauchen.
Drittens: Das Fundament ist Open Source plus Abo, nicht Cloud-Lock-in. Linux, SQLite, Markdown, Git, Obsidian, alles kostenlos. Einzige gebundene Komponente: mein Claude-Abo. Wenn Anthropic die Preise verdoppelt, wechsle ich das Modell, nicht die Architektur. Das ist ein anderes Dependency-Profil als jede SaaS-Plattform.
Gerechtfertigte Kritik bleibt trotzdem: Die aktuellen Abos sind von den Anbietern subventioniert; Token-Kosten könnten steigen. Sicherheit ist für Enterprise-Szenarien ein ungelöstes Feld. Für Solo- und Klein-Setups mit unkritischen Daten ist der Hebel aber schon heute real, und das ändert, wer in den nächsten zwei Jahren wirtschaftlich überhaupt mithalten kann.
Für wen dieser Beitrag taugt, und für wen nicht
Ein Solo-Setup ist kein Konzern-Setup. Was bei mir funktioniert, lässt sich nicht einfach auf hundert Mitarbeitende übertragen. In Unternehmen kommen Themen dazu, die bei mir schlicht wegfallen: wer darf was mit welchen Daten sehen, wie integriert man zwanzig Jahre alte Systeme, wie sieht Governance für DSGVO und EU AI Act aus, wie trainiert man hundert Leute, die noch nie produktiv mit KI gearbeitet haben. Das sind andere Baustellen, nicht schwerer, aber anders.
Trotzdem lohnt der Blick auf Solo-Setups auch für Unternehmen als Referenz: Was ist der State of the Art, wenn jemand alleine und ohne die üblichen Bremsen baut? Vieles davon ist direkt auf einen kleinen internen Piloten übertragbar.
Mein Rat dafür: eine Ebene vor dem großen Transformationsprojekt ansetzen. Zwei bis vier Mitarbeitende, die Lust auf das Thema haben. Klar abgegrenzte, unkritische Use Cases, Marktrecherche, Wettbewerbsbeobachtung, Content, Leadqualifizierung, internes Wiki. Keine personenbezogenen Daten, keine Kundendaten. Ein paar Lizenzen, ein alter Rechner, zwei bis vier Wochen ernsthafte Nutzung. Der Wert liegt weniger im unmittelbaren Output als im Erfahrungsaufbau. Wer jetzt startet, weiß in einem Jahr, was geht und was nicht, und muss nicht raten.
Dieser Beitrag beschreibt das Solo-Ende. Vieles davon lässt sich auf einen Klein-Piloten übertragen, einiges nicht. Den Unterschied sollten Sie beim Lesen im Kopf behalten.
Ist das überhaupt relevant für mich?
Eine Studie mit 758 Wissensarbeitenden zeigt: Innerhalb der sogenannten Jagged Frontier (also bei Aufgaben, die KI gut kann) erledigen Menschen mit KI-Unterstützung 12,2 Prozent mehr Aufgaben und sind 25,1 Prozent schneller. Außerhalb dieser Grenze produzieren sie 19 Prozentpunkte seltener korrekte Lösungen (Dell'Acqua et al., 2023). Die Grenze ist nicht stabil. Sie wandert, je nach Modell-Generation.
Zur Verbreitung: Eine Sonderauswertung des KfW-Mittelstandspanels zeigt, dass zwischen 2022 und 2024 bereits 20 Prozent der mittelständischen Unternehmen in Deutschland KI eingesetzt haben; zwischen 2016 und 2018 waren es erst vier Prozent (KfW Research, 2026). Bitkom meldet parallel, dass 41 Prozent der Unternehmen ab 20 Beschäftigten KI bereits nutzen und weitere 48 Prozent den Einsatz planen oder diskutieren (Bitkom Research, 2026). Das passt zu meinem Eindruck: Viele diskutieren, wenige bauen. Dieser Beitrag richtet sich an die Bauenden.
Was ist ein Multi-Agent-System, und was genau unterscheidet es von ChatGPT?
Kurz gesagt: Ein Chatbot beantwortet eine Frage im Gespräch. Ein Multi-Agent-System arbeitet in einem dauerhaften Kontext: mit Dateien, Datenbank, Regeln, Prüfungen und wiederverwendbaren Arbeitsabläufen.
Ein Multi-Agent-System ist eine Architektur, in der mehrere spezialisierte KI-Agenten auf einem gemeinsamen Wissensspeicher arbeiten, Aufgaben untereinander übergeben und sich gegenseitig ergänzen. Der Unterschied zu einem einzelnen Chatbot: Spezialisierung, Parallelverarbeitung und geteilter Kontext.
Wichtiger als die Definition ist die Abgrenzung. Ein Multi-Agent-System ist kein autonomes System, das eigenständig entscheidet. Ich gebe frei. Ich validiere. Es ist kein Ersatz für menschliches Urteil bei strategischen Fragen.
Und: Mehr Agenten sind nicht automatisch besser. Google Research, 2026 hat 180 Agenten-Konfigurationen untersucht und kommt zu einem Muster, das meine Praxis sehr gut erklärt: Multi-Agent-Koordination hilft vor allem bei parallelisierbaren Aufgaben. Bei streng sequenziellen Aufgaben kann sie deutlich schaden, weil Koordination selbst Denkbudget verbraucht. Für mein System heißt das: Ein starker Agent mit gutem Kontext ist der Normalfall; mehrere Agenten sind ein Spezialwerkzeug.
Ehrlich: Eine gewisse Black Box bleibt es trotzdem. Ein Sprachmodell ist im Kern immer eine. Mein System wird zusätzlich zu einer, weil ich bei über 110 Fach-Tabellen und mehr als vierzig Automatisierungen längst nicht mehr jeden Schritt einzeln prüfe; dieses Restrisiko trage ich bewusst.
Was es vom ChatGPT- oder Gemini-Chatfenster unterscheidet, ist fundamental und wird oft unterschätzt. Im Browser-Chat reden Sie mit einer KI, die nach dem Gespräch fast alles wieder vergisst. Memory-Funktion aktivieren, Dateien manuell hochladen, das geht, aber die KI bleibt eine Gesprächspartnerin. In meinem System ist Claude ein Kollege mit Zugang zum Büro. Die KI legt Dateien an, aktualisiert sie, führt Datenbankabfragen aus, startet Hilfsprogramme, schreibt ihre eigenen wiederverwendbaren Arbeitsabläufe (in der Fachwelt Skills genannt) und dokumentiert, was sie getan hat.
Das Wissen wächst dabei fast vollautomatisch. Jedes neue Paper, jeder Chat mit mir, jede Rückmeldung zu einem Ergebnis fließt zurück ins System, und es wird mit jedem Zyklus besser. Aus einer einmaligen Antwort wird dauerhaftes Wissen. Wenn ich ChatGPT eine Studie gebe, kann es sie im Gespräch analysieren. Wenn ich meinem System eine Studie gebe, landet sie in der Evidenz-Datenbank, wird gegen existierende Einträge geprüft, bekommt ein Konfidenz-Level, wird mit relevanten LinkedIn-Posts und Blog-Themen verknüpft und steht ab sofort bei jeder Recherche zur Verfügung.
Und es gibt einen Punkt, der für mich der größte Unterschied ist: die fast absolute Gestaltungsfreiheit. Ich entscheide, welche Tabellen entstehen, welche Skills es gibt, wie die Qualitäts-Gates aussehen, welche Prozesse automatisch laufen. Kein Produkt-Backlog, kein Hersteller, der über meine Workflows bestimmt. Man baut sich im Prinzip sein eigenes, maßgeschneidertes KI-Betriebssystem für den eigenen Arbeitsbereich. Das ist die Stärke, und gleichzeitig das Risiko, weil die KI deutlich mehr kann und anrichtet als im Browser.
Warum habe ich mir das gebaut und wofür nutze ich es wirklich?
Kurz: Ich bin Solo-Berater mit Microsoft-365-Governance und KI-Readiness als Spezialgebiet. Kein Team, das mit mir skaliert. Keine Beratungs-Infrastruktur, die sich selbst finanziert. Was mir fehlt, ist Hebel. Was ich mir gebaut habe, ist dieser Hebel in Software.
Die Motivation ist nicht Hype, sondern ein konkretes Problem: Content produzieren, Leads recherchieren, Studien auswerten, Entscheidungen dokumentieren. Das alles frisst Zeit, die ich als Einzelperson nicht habe. Jedes klassische Werkzeug löst davon einen Teil. Mein Multi-Agent-System versucht, die Teile zusammenzubringen.
Konkret nutze ich das System heute in sieben Bereichen:
Content und Kommunikation: LinkedIn-Posts entwerfen, Blogbeiträge strukturieren, Themen-Pipeline pflegen, SEO-/GEO-Hinweise prüfen und Fakten-Gates vor Veröffentlichung ausführen.
Wissensmanagement und Recherche: Deep Researches zu Microsoft Copilot, KI-Sicherheit oder DSGVO verarbeiten, wissenschaftliche PDFs extrahieren, OpenAlex-Daten ergänzen und Erkenntnisse in einer Evidenz-Datenbank verdichten.
Strategie und Entscheidungen: OKRs, Wochenfokus, Risk Register und aktuell über 40 ADRs pflegen, damit Entscheidungen später nachvollziehbar bleiben.
Sales und Leads: Unternehmen im DACH-Mittelstand identifizieren, anreichern und mit nachvollziehbarer Datenherkunft bewerten. Aktuell liegen 67 Leads im System.
Freelancer- und Markt-Screening: 137 Projekte wurden bisher automatisch analysiert; nur relevante Ausschreibungen landen bei mir.
Reporting und Analytics: KPI-Definitionen zentral halten, Website- und Social-Media-Signale einordnen, Wochen- und Monatsberichte aus Daten statt aus Bauchgefühl erzeugen.
Security, Monitoring und Selbstverbesserung: Health-Checks, Sicherheitsfeeds, Backup-Signale, Skill-Bewertungen und ein Fehler-Gedächtnis betreiben, damit derselbe Fehler nicht immer wieder neu passiert.
Die grobe Formel lautet: Domänen geben dem System die Arbeitsbereiche, Layer geben ihm Reihenfolge und Verantwortung, CCCs geben ihm die Prüffragen. Ohne diese drei Ebenen wäre es nur eine schnelle Tool-Sammlung. Mit ihnen wird es ein System, das lernen, prüfen und sich selbst korrigieren kann.
Was mir das messbar bringt:
Strukturumbauten an Datenbank oder Prozessen dauern in der Regel 20 bis 40 Minuten, nicht Tage. Beispiel aus der letzten Woche: Schema-Migration über sechs Apps, kein einziger Integritätsfehler, Zeitaufwand rund eine Stunde.
Nachvollziehbarkeit: Für jede Zahl in meinen Beiträgen kann ich Primärquelle, Konfidenz-Level und Verifikations-Datum nennen.
Seit Wochen kein kritischer Systemausfall, obwohl das System täglich erweitert wird.
Was mir das nicht bringt (ehrlich):
Kein Automatismus auf der Ergebnisseite. Das System macht mich schneller und gründlicher, nicht automatisch erfolgreicher. Der Unterschied ist mir wichtig: Es nimmt mir Prozess-Arbeit ab und schafft Zeit für das, was Software nicht kann, Beziehungen aufbauen, Vertrauen gewinnen, echte Gespräche führen. Business-Outcomes garantiert dir kein Werkzeug der Welt. Das schafft man auch mit großen Teams oft nicht. Das System ist Infrastruktur, kein Umsatztreiber an sich. Es macht aber möglich, dass ich als Einzelperson Themen bearbeite, für die sonst ein dreiköpfiges Team nötig wäre.
"Erst die Daten sauber, dann KI"? Nein.
Ein Einwand hält sich hartnäckig: Man müsse erst die Daten und Prozesse sauber bekommen, dann komme KI. Das Gegenteil ist meine Erfahrung. Wer auf diesen Zustand wartet, wartet für immer. Strukturiertes Wissen hilft, ist aber kein Muss. Grüne Wiese geht auch. Am Anfang macht man viele Fehler, die Security ist noch nicht gehärtet, Prozesse wackeln. Damit kann man arbeiten, solange die KI einen schlechten Prozess in 20 bis 40 Minuten anpassen kann. Ich habe meine Datenbank, meine Apps und meine Skill-Architektur so oft umgebaut, dass ich aufgehört habe zu zählen.
Niemand kann die Zukunft vorhersagen. Vielleicht ist dieser Blogbeitrag in wenigen Wochen in Teilen überholt, weil ein einfacheres oder besseres Werkzeug auf den Markt kommt. Der echte Hebel, den ich heute sehe, ist deshalb ein anderer: die systematische Erzeugung von Unternehmenswissen und Kontext für zukünftige KI-Modelle. Und damit meine ich nicht tausend PowerPoints und Word-Dateien im SharePoint. Ich meine hochrelevante, aktuelle, möglichst hochwertige Insights, Lessons Learned aus internen und externen Signalen, dokumentierte Entscheidungen mit Begründung, verifizierte Evidenz mit Konfidenz-Level. Genau dieser Kontext ist das, was das nächste Modell in zwölf Monaten braucht, um in Ihrem Unternehmen wirklich wertvoll zu sein. Wer heute damit anfängt, sammelt ihn laufend. Wer in zwei Jahren einsteigt, hat ein besseres Modell, aber nichts, womit es arbeiten kann.
Meine Lernkurve: vom Agenten-Framework zurück zum Terminal
Angefangen habe ich im Februar 2026 auf dem ehrgeizigsten Weg: mit einem eigenen Agenten-Framework namens OpenClaw. Mehrere Agenten, Discord als mobiles Frontend, eigene API-Aufrufe, selbstgebautes Tooling. Ich war zwei Wochen tief im Code, bis das Ding überhaupt rudimentär lief. Ein schönes Lehrstück, aber ehrlich: zu viel Architektur, zu wenig Ergebnis. In diesen ersten Wochen war ich mehrfach kurz davor, alles hinzuwerfen. Das gehört zur Wahrheit dazu. Wer den Einstieg plant, sollte wissen, dass dieses "das wird nie funktionieren"-Gefühl Teil des Weges ist.
Parallel habe ich immer mehr mit Claude im Browser gearbeitet, weil es schlicht schneller war. Irgendwann waren meine OpenClaw-Agenten in Discord nur noch Benachrichtigungs-Kanäle für Alerts.
Der eigentliche Sprung kam dann mit Claude Code im Terminal. Plötzlich konnte ich Probleme lösen, an denen die eigenen Agenten reihenweise scheiterten: komplexe Refactorings, Schema-Migrationen, Debugging über mehrere Dateien hinweg. Das Tool arbeitet direkt in meinen Ordnern, hat Zugriff auf alle Werkzeuge des Systems und denkt in größerem Kontext als jede API-Schleife, die ich mir selbst zusammengestrickt habe.
Vor wenigen Tagen habe ich OpenClaw komplett abgebaut. Der einzige spürbare Nachteil: Mobile-Arbeit fällt weg. Vom Handy aus lässt sich Claude Code im Terminal nicht wirklich bedienen, und das ist okay für mich, weil ich die Hand am echten Rechner habe, wenn ich baue. Alles andere: messbar besser.
Aus dieser Erfahrung sind zwei Ebenen plus zwei Ergänzungen übrig geblieben:
Ebene 1, Claude.ai im Browser (alternativ Gemini oder ChatGPT). Das Gespräch mit einem klugen Berater. Ich tippe, bekomme Antworten, lade mal eine PDF hoch. Gut für Recherchen, Strategiegespräche, Brainstorming. Diese Ebene kennen die meisten.
Ebene 2, Claude Code im Terminal. Der eigentliche Handwerker. Die KI arbeitet direkt auf meinem Rechner: liest Dateien, schreibt Dateien, führt Befehle aus, debuggt. Hier findet der gesamte Aufbau statt. Einstieg ab Pro-Abo (rund 18 Euro pro Monat). Für ernsthafte Nutzung empfehle ich inzwischen den Max Plan, dazu später mehr.
Ergänzung 1, Obsidian als menschliches Frontend. Ein kostenloser Markdown-Editor mit Graph-Ansicht. Bei mir auf Windows, synchronisiert per Git mit dem Linux-Server. Ich browse und denke visuell auf dem Laptop, der Agent arbeitet serverseitig, beide auf denselben Dateien. Kein Muss, aber Gold wert für den menschlichen Überblick.
Ergänzung 2, Discord für Push-Benachrichtigungen. Kein KI-Chat, sondern ein Meldekanal: Sicherheitswarnungen, neue Freelancer-Ausschreibungen, fehlgeschlagene Automatisierungen. Das System meldet sich, wenn etwas wichtig ist. Kein aktives Befragen, nur Push aufs Handy.
Meine Empfehlung: Fangen Sie mit Ebene 1 und 2 an. Obsidian und Discord dazu, wenn das Fundament steht. Keine eigenen Agenten-Frameworks, keine Telegram-Bots, keine API-Bastelei am Anfang. Ich habe das alles probiert und in den ersten Tagen rund 30 Euro verbrannt, weil die KI ohne klare Struktur wild Dateien angelegt hat. Ohne Fundament entsteht Chaos, nicht irgendwann, sondern sofort.
Die Ebenen-Logik habe ich in einem früheren Beitrag ausführlicher beschrieben: KI-Strategie im Mittelstand: Warum Sie kein Transformationsprojekt brauchen.
Multi-Agent-System aufbauen: Das Fundament (Hardware, Terminal, Shared Folder)
Phase 1: Wegwerf-Hardware und Minimal-Security
Nehmen Sie einen alten PC oder Laptop. Installieren Sie Ubuntu 24.04. Legen Sie mehrere Benutzer an: einen für sich selbst, einen für die KI-Umgebung (Principle of Least Privilege). Keine kritischen Daten auf diesen Rechner. Tägliches Backup einrichten. Fertig.
Das Wichtigste klingt erst mal falsch: Geben Sie der KI in der Aufbauphase möglichst viele Rechte. Ja, das widerspricht jeder Security-Lehre. Aber wer der KI während des Aufbaus alles verbietet, debuggt wochenlang statt zu bauen. Das Risiko ist dadurch kleiner, aber nicht null. Wer ehrlich ist, räumt ein: Absolute Sicherheit gibt es nicht. Der Schaden bleibt aber begrenzt, wenn weder Kundendaten noch Geschäftsgeheimnisse auf der Maschine liegen. Mehr zu Security folgt in Teil 3.
Technisches Briefing für Ihr LLM (Basis-Setup, Kopiervorlage):
Kontext: Ubuntu 24.04 LTS auf einem Einzelrechner, KI-Agenten-System für eine
Solo-Nutzerin. Keine Kundendaten, keine kritischen Daten, kein Produktivbetrieb
für Dritte. Bitte keine Secrets ins Repo schreiben und keine destruktiven
Aktionen ohne explizite Rückfrage vorschlagen.
Bitte erklären und als idempotente Schritt-für-Schritt-Anleitung umsetzen:
- Zwei Benutzer anlegen: einen persönlichen Account (uid 1000) und einen
separaten Systemuser für die KI-Automation. Gemeinsame Gruppe, setgid-Bit
auf dem Arbeitsverzeichnis, damit beide dort schreiben können.
- Trennung von Code und Laufzeitdaten: Repo unter /srv, Secrets in /etc/<app>,
State unter /var/lib/<app>, Logs unter /var/log/<app>, Backups unter
/var/backups/<app>. Keine Laufzeitdaten ins Git-Repo.
- SSH absichern: PasswordAuthentication=no, nur Public-Key-Login, Root-Login
gesperrt. UFW aktivieren: default deny incoming, SSH rate-limited, alles
andere gezielt freigeben.
- unattended-upgrades für Security-Updates aktivieren.
- Tägliches Backup: borgbackup oder restic, verschlüsselt und dedupliziert,
Retention 7 täglich / 4 wöchentlich / 12 monatlich.
Bitte für jeden Punkt liefern: Begründung, häufige Fallstricke, ein
Verifikationskommando und ein Minimalbeispiel. Fortgeschrittene Härtung
(AppArmor, systemd-Sandboxing, Least-Privilege-sudoers) separat als Phase 2
vorschlagen, nicht vermischen.Phase 2: Claude Code im Terminal statt APIs
Claude Code ist ein Kommandozeilen-Werkzeug von Anthropic, das direkt auf Ihren Ordnern arbeitet. Kein API-Key-Gebastel, keine Python-Skripte. Sie schreiben einen Satz, die KI macht den Rest: liest Dateien, schreibt Dateien, führt Befehle aus.
Der Vorteil gegenüber APIs oder günstigen Modellen: Sie bekommen sofort das stärkste verfügbare Modell (Opus oder Sonnet), planbare Fixkosten im Abo und volle Kontrolle über den Kontext. Sie sehen jeden Schritt. Wer APIs mit billigen Modellen kombiniert, spart an der falschen Stelle: mehr Debugging-Zeit als Kosten-Ersparnis.
Technisches Briefing für Ihr LLM (Einstieg mit Claude Code):
Kontext: Claude Code CLI als primäre Arbeitsumgebung auf meinem Rechner. Ich
will zuerst ein robustes Solo-System bauen, kein Agenten-Framework.
Bitte erklären und vorschlagen:
- Was unterscheidet Claude Code von reiner API-Nutzung? Welche Vorteile bekomme
ich konkret durch Kontextmanagement, Tool-Zugriff, Dateisystemarbeit und
Slash-Commands?
- Projektweite Agent-Instruktionen: AGENTS.md/CLAUDE.md oder vergleichbare
Repo-Regeln. Wo platzieren, was gehört hinein (Konventionen, Pfade, Verbote,
Sicherheitsgrenzen), was gehört nicht hinein (ephemere Tasks, Secrets,
private Tokens)?
- Modell-Wahl: stärkstes Modell für Architektur, Refactors und unklare
Entscheidungen; günstigeres/schnelleres Modell für Lookups und Routine.
Bitte als einfache Entscheidungsregel formulieren, nicht als Dogma.
- Git-Grundregeln: kleine Commits, keine Secrets, Review vor riskanten
Änderungen, kein externer Push ohne Freigabe.
- Optional: zweites Modell oder Codex als Review-Instanz, aber erst nachdem das
Grundsystem stabil ist.
Mein Ziel: [Anwendungsfall in einem Satz]. Schlag auf dieser Basis eine
minimale Projektstruktur mit Repo-Root, Wissensbereich und Runtime-Bereichen vor
und begründe jede Entscheidung. Fortgeschrittenes (MCP-Server, Subagenten,
Hooks, eigene Skills) separat für eine zweite Runde vorschlagen.Phase 3: Shared Folder und das Blackboard-Prinzip
Legen Sie einen gemeinsamen Workspace oder Vault an und strukturieren Sie ihn nach Themen. Jeder Unterordner bekommt eine README.md, die beschreibt, was drin liegt und wofür. Diese README ist nicht nur für Sie. Sie ist vor allem für die KI.
Das Blackboard-Prinzip stammt aus der KI-Forschung der 1980er-Jahre: Mehrere Agenten lesen und schreiben auf einem gemeinsamen Speicher. Bei mir ist das eine README.md pro Ordner. Das bleibt simpel und trägt auch, wenn das System wächst. Die Agenten lesen vor jeder Aufgabe, aktualisieren danach. So entsteht ein System, das sich selbst dokumentiert.
Obsidian dockt hier an. Auf meinem Windows-Laptop ist der Shared Folder ein Obsidian-Vault, dasselbe Verzeichnis, das auf dem Linux-Server liegt, synchronisiert via Git. Ich sehe eine Graph-Ansicht aller Dokumente, springe per Wiki-Links zwischen Notizen, editiere unterwegs. Die KI liest und schreibt dieselben Dateien auf der Server-Seite. Zwei Perspektiven auf einen Wissensspeicher, die menschliche (visuell, assoziativ) und die maschinelle (strukturiert, über Metadaten).
Der Effekt ist messbar. Das ACE Framework (Zhang et al. 2025, arXiv:2510.04618) zeigt: Kontexte als "evolving playbooks" zu behandeln verbessert Agent-Benchmarks um 10,6 Prozent. Ein gut gepflegter Shared Folder ist genau das: ein mitwachsender Wissensspeicher, der mit jedem Durchlauf besser wird.
Aktuelle Memory-Forschung geht in dieselbe Richtung. MIRIX, 2025 unterscheidet sechs Memory-Typen: Core, Episodic, Semantic, Procedural, Resource Memory und Knowledge Vault. Das klingt akademisch, trifft aber einen praktischen Punkt: Ein Agent braucht nicht nur "Erinnerung", sondern unterschiedliche Speicherarten für Regeln, Erfahrungen, Fakten, Verfahren und Quellen. Genau deshalb trenne ich Markdown-Wissensbasis, Evidence-Datenbank, Skills, ADRs und Runtime-Daten.
Die Analogie zu Niklas Luhmanns Zettelkasten (Luhmann 1981, Kommunikation mit Zettelkästen. Ein Erfahrungsbericht) liegt nahe. Was Luhmann mit seinem vernetzten Notizsystem erreichte, kleine Wissens-Einheiten, die sich gegenseitig referenzieren, erreicht ein Multi-Agent-System mit README-Dateien und Frontmatter-Metadaten. Nur dass jetzt ein Sprachmodell durch den Zettelkasten navigiert.
Technisches Briefing für Ihr LLM (Wissens-Ordner als Blackboard):
Kontext: Markdown-basierter Workspace/Vault, an dem ein oder mehrere Agenten
arbeiten. Basis: Blackboard-Architektur, angepasst für moderne Agent-Systeme.
Bitte erklären und Beispiele generieren:
- YAML-Frontmatter als einheitlicher Header für jedes Dokument: id,
content_type (z.B. adr/skill/evidence/project/note), status, created_at,
updated_at, source, review_in, related und llm_summary. Die llm_summary soll
in einem Satz erklären, ob ein Agent die Datei für eine Aufgabe laden muss.
- Eine zentrale Router-Datei (HOME.md, AGENTS.md/CLAUDE.md oder vergleichbar)
mit thematischen Clustern, pro Cluster 3-5 Einstiegspunkte. Agenten lesen
zuerst den Router, nicht das gesamte Verzeichnis.
- Lazy Loading: erst llm_summary und README prüfen, dann gezielt nachladen.
Keine automatische Volltext-Wanderung durch den ganzen Vault.
- Jede README mit einem klaren Zweck, Scope-Grenzen, erlaubten Inhalten und
typischen Suchbegriffen.
- .gitignore: Laufzeitdaten (Datenbanken, node_modules, Logs, Exporte) raus aus
dem Repo.
Generiere: eine Muster-AGENTS.md/CLAUDE.md, eine README-Vorlage und eine
Frontmatter-Spezifikation. Optional später: Schema-Validator oder Pre-Commit-
Check gegen Pflichtfelder.Ich habe eine ganze Woche nur an diesem Fundament gearbeitet. Das war keine verlorene Zeit. Das war die beste Investition des ganzen Projekts.
Was mich am meisten überrascht hat: Etwa 80 Prozent meiner Zeit mit diesem System gehen in Architektur, nicht in das eigentliche Tun. Das klingt ineffizient. Ist es nicht. Wer die Architektur nicht investiert, zahlt sie doppelt später.
Wie dokumentieren Sie Wissen in einem Multi-Agent-System?
Jede Entscheidung wird als kurzes ADR (Architecture Decision Record) festgehalten. Jede wiederkehrende Aufgabe als Skill (Markdown-Prozessbeschreibung). Recherchen landen als Deep-Research-Dokumente mit Konfidenz-Level in der Wissensbasis. So entsteht ein System, das sich selbst erklärt.
Phase 4: ADRs für Entscheidungen
Nach drei Wochen fragen Sie sich: Warum haben wir das damals so entschieden? Das ADR-Konzept wurde von Michael Nygard in seinem Essay Documenting Architecture Decisions (Nygard 2011) eingeführt. Ein ADR ist ein kurzes Dokument, das festhält, was entschieden wurde, warum, welche Alternativen verworfen wurden und was die Konsequenzen sind. Eine halbe Seite reicht. Es klingt bürokratisch, funktioniert bei mir aber als Unternehmensgedächtnis. Ich habe heute über 40 ADRs, und ich lese regelmäßig darin nach.
Phase 5: Wissensmanagement als Multiplikator
Wissen ist das Futter für das System. Je besser das Wissen, desto besser die Outputs. Mein Ansatz hat drei Säulen:
Deep Research für jedes neue Thema (in Claude.ai, Gemini oder ChatGPT). Ergebnis als Markdown in einen Wissens-Ordner. Primärquellen ziehe ich automatisch als PDF nach, konvertiere sie mit pymupdf4llm in Markdown und reichere Zitationsnetzwerke über die offene Forschungsdatenbank OpenAlex an.
Evidence-Datenbank mit Konfidenz-Stufen: citation_ready, content_matched, raw, debunked. Mein Stand heute: 859 Einträge, 73 davon direkt zitierfähig, 38 widerlegt. Was als widerlegt markiert ist, darf das System nie verwenden.
Skills als wiederverwendbare Prozessbeschreibungen. Wer einen Vorgang mehr als dreimal macht, schreibt einen Skill.
Mein häufigster Lernmoment: KI-Recherchen zitieren Studien falsch. Nicht immer, aber regelmäßig. Drei Gegencheck-Runden sind Pflicht, bevor eine Zahl in einem Beitrag landet. Wie ich Fakten im System systematisch prüfe, habe ich in einem eigenen Beitrag beschrieben: KI-Faktenprüfung: Wie ein Wissenssystem Fakten prüft, bevor sie in deinem Feed landen.
Zu den Agenten selbst eine wichtige Warnung, die ich am Anfang unterschätzt habe: Weniger ist oft besser. Anthropic formuliert es in Building effective agents, 2024 sehr nüchtern: Erst die einfachste Lösung bauen; viele Anwendungsfälle brauchen gar kein Agentensystem, sondern ein gutes LLM mit Retrieval, Tools und klaren Workflows. Das deckt sich brutal gut mit meinem OpenClaw-Umweg.
Die Gegenbeispiele sind wichtig: Anthropic berichtet bei einem Research-Agenten von 90,2 Prozent besserer Leistung gegenüber einem Single-Agent-Setup, aber auch von etwa 15-fachem Token-Verbrauch (Anthropic Engineering, 2025). Google Research zeigt parallel: Bei parallelisierbaren Aufgaben kann zentrale Koordination stark helfen, bei sequenzieller Planung können Multi-Agent-Varianten um 39 bis 70 Prozent schlechter abschneiden (Google Research, 2026). Die richtige Frage lautet also nicht: "Wie viele Agenten?", sondern: "Ist diese Aufgabe wirklich parallel zerlegbar?"
Meine ehrliche Empfehlung: Für den Aufbau reicht ein Agent. Claude Code im Terminal. Mehr nicht. Weitere Agenten sind erst sinnvoll, wenn Sie wirklich parallelisieren müssen (zum Beispiel zehn Leads gleichzeitig anreichern) oder wenn ein klar umgrenzter Teilprozess oft genug wiederkehrt. Wenn es dann soweit ist, gilt: enger Aufgaben-Zuschnitt schlägt den Universal-Agenten. Mehr zu den belegten Fehlerklassen steht in Teil 2: Multi-Agent-System Schwächen: 5 Anfänger-Fehler und 5 belegte Risiken.
Technisches Briefing für Ihr LLM (neuer Skill):
Kontext: Ich möchte einen wiederkehrenden Arbeitsablauf als Skill festhalten.
Ein Skill ist eine kurze Prozessbeschreibung, die ein Agent selbstständig
ausführen kann.
Bitte erklären und gemeinsam entwerfen:
- Sniper-Prinzip: ein Skill, ein klarer Zweck. Kein Universal-Workflow.
Mehrere schmale Skills schlagen einen breiten.
- Frontmatter, das der Agent wirklich braucht: name und description als
Trigger-Signal; optional input_contract, output_contract, error_patterns und
llm_summary, wenn das lokale Skill-System diese Felder nutzt.
- Workflow in Phasen: Vorbedingungen, Recherche/Lesen, Ausführung, Prüfung,
Ausgabeformat.
- Self-Check am Ende: Der Skill prüft selbst, ob sein Output dem Contract
entspricht. Nicht erst der nächste Prozessschritt.
- Messung: 3-5 einfache Pass/Fail-Assertions, damit Regressionen auffallen.
- Versionierung: jeder Skill in Git, Änderungen mit Grund dokumentieren.
Mein Prozess: [Input-Quellen, Schritte, Output-Format]. Bitte generiere eine
Skill-Datei nach diesem Rahmen inklusive Fehlerfällen und Self-Check.
Fortgeschrittenes (Toulmin für Analyse-Skills, Sycophancy-Gegenprüfung,
Regression-Ceiling) separat als Erweiterung vorschlagen, nicht mischen.Phase 6: Frühzeitig eine zentrale Datenbank aufsetzen
Textinformationen gehören ins Dateisystem, strukturierte Daten in eine Datenbank. Ich habe anfangs auf eine Datenbank verzichtet ("Overengineering für einen alleine"). Das war mein größter struktureller Fehler.
Wichtiger Hinweis: Nicht am ersten Tag. In Woche eins baut man noch am Fundament, Ordnerstruktur, erste Skills, Gefühl für das Tooling. Aber spätestens nach einer Woche lohnt es sich, SQLite einzuziehen. Wer damit zu lange wartet, sammelt Daten in JSON-Dateien und zahlt später doppelt.
Konkret: Mein System lief vor der Migration auf sechs getrennten JSON-Dateien. Von 111 Aufgaben waren nur 17 mit einem Ziel verknüpft, nicht weil jemand vergessen hätte zu verlinken, sondern weil die Struktur es nicht konnte. Abfragen über mehrere Datenbereiche waren unmöglich. Backups deckten sechs Dateien ab, aber keine Beziehungen zwischen ihnen. Meine heute 116 Tabellen sind nicht überdimensioniert, sie sind die Grundlage für jedes Reporting und jede Automatisierung. Claude baut das Schema; Sie benennen nur die Entitäten und Beziehungen.
Technisches Briefing für Ihr LLM (SQLite-Fundament):
Kontext: SQLite als zentrale Datenbank für ein KI-Agenten-System auf einem
Rechner. Meist schreibt nur ein Prozess gleichzeitig. Bitte erklären und ein
Start-Schema vorschlagen:
- Wichtige PRAGMAs mit Begründung: journal_mode=WAL, foreign_keys=ON,
synchronous=NORMAL, busy_timeout. Kurz: was macht jeder Schalter, und warum
ist er für ein Solo-Setup sinnvoll?
- STRICT tables für Typensicherheit.
- Foreign Keys mit bewusster ON DELETE-Regel, Indexe auf Fremdschlüsseln und
sinnvolle UNIQUE-Constraints.
- Einfacher Audit-Trail über Trigger, der Änderungen in eine audit_log-Tabelle
schreibt, ohne Geschäftslogik in Triggern zu verstecken.
- Schema-Migrationen in versionierten Dateien plus schema_versions-Tabelle mit
Checksumme, damit Drift sichtbar wird.
- Backups über die .backup-API oder einen konsistenten Backup-Wrapper; Restore
regelmäßig testen.
- Häufige Anti-Patterns: JSON-Blobs als Mülleimer, fehlende Constraints,
überladene Trigger, unklare Besitzer je Tabelle.
Mein System: [3-5 konkrete Anwendungsfälle]. Schlage 5-8 Start-Tabellen vor
mit Zweck, Spalten, Typen, Indexen und Beziehungen. Danach: vollständiges
SQL-Schema als Init-Skript plus zwei Beispielabfragen, die zeigen, warum die
Struktur besser ist als einzelne JSON-Dateien.Skalierung: Apps, Reporting, Automatisierung
Phase 7: Lokale Apps als menschenfreundliche Anzeigen
Ab einem bestimmten Datenumfang verlieren Sie den Überblick. Dann kommen lokale Web-Apps. Meine sechs Apps haben kaum noch Buttons. Sie sind vor allem Anzeigeflächen für die Daten aus Datenbank und Dateisystem. Der einzige dauerhafte Button: "An Agenten übergeben" kopiert den Kontext ins Terminal. Das ist die effizienteste Arbeitsweise, die ich gefunden habe.
Phase 8: Einheitliches Reporting
Sobald Daten fließen, wollen Sie messen. Mein Fehler war: unterschiedliche Reporting-Logik in verschiedenen Apps für dieselbe Kennzahl. Heute gibt es ein zentrales KPI-Register mit Definition und Berechnungsvorschrift. Jede App zieht daraus. Wer das von Anfang an macht, spart sich Wochen an Konsolidierung.
Phase 9: Automatisierung, Selbstverbesserung und Monitoring
Über 40 Cron-Jobs laufen bei mir nachts: Wissensmanagement aufräumen, Skills automatisch testen und verbessern, Datenbank-Konsistenz prüfen, Erkenntnisse der Woche zusammenfassen. Das funktioniert nicht immer perfekt, und es hat klare Grenzen (dazu in Teil 2). Aber wenn ich einen Verdacht habe, sage ich: "Mach mal eine Analyse." Das System findet meistens, was ich suche. Manchmal auch, was ich gar nicht gesucht habe.
Ohne ständiges Überwachen geht das nicht. Und ehrlicherweise zählt Bauchgefühl: Wenn mir etwas komisch vorkommt, weise ich das System darauf hin, meistens findet es dann alle Details. Deshalb sind Automatisierung und Monitoring kein Luxus, sondern die Brille, mit der ein Einzelner überhaupt noch den Überblick behält. Blinde Flecken bleiben trotzdem. Die gibt es bei Menschen auch.
Wie weit dieser Gedanke trägt, zeigt sich in einem eigenen Unterprojekt: Das System verbessert seine eigenen Prozesse, misst die Verbesserung und behält nur, was wirklich besser ist. Details dazu folgen in einem späteren Beitrag.
Mein Messwerkzeug: jede Skill-Ausführung wird bewertet. Aktuell über 2.000 Evaluations, Durchschnitt 0,84, Spannbreite von 0,61 (der leads-Skill, klar das Schlusslicht) bis 1,00 (zum Beispiel fact-check). Transparenz über Schwächen ist mir wichtiger als Behauptungen über Stärken.
Der wichtige Punkt: Ich bewerte nicht nur den fertigen Text. Anthropic, 2026 beschreibt Agenten-Evaluierung als Kombination aus Aufgabe, Trial, Grader, Transcript, Outcome und Harness. Genau das ist der Unterschied zwischen "fühlt sich besser an" und "ist belastbarer geworden". Bei meinen Skills zählen deshalb nicht nur schöne Antworten, sondern auch: Wurde die richtige Quelle gelesen? Wurde der richtige Zustand verändert? Kam am Ende ein nutzbares Artefakt heraus?
Phase 10: Aufgabenmanagement (kurz gehalten)
Am Anfang reicht eine Markdown-Datei. Später: eine Tabelle mit App. Ein Agent braucht zu wissen, was als Nächstes ansteht. Ohne das läuft er im Kreis oder erfindet Aufgaben. Wichtig: Aufgaben mit OKRs oder Projekten verknüpfen, damit der Agent versteht, worauf eine Aufgabe einzahlt.
Die größte Unbekannte: den richtigen Kontext geben
Nach zwei Monaten ist meine ehrliche Einschätzung: Die größte Unbekannte sind nicht die Modelle. Es bin ich. Ob ich die richtigen Ziele, Vorgaben, Projekte und Aufgaben gebe, das entscheidet über Erfolg oder Sackgasse mehr als jedes Architektur-Detail. Die KI wird nicht von allein sagen "ich glaube, du verrennst dich, XY wäre jetzt besser". Und das obwohl ich mein System explizit dazu ermuntere, anhand von Daten zu bewerten und eigene Vorschläge zu machen. Aktuell muss ich Ideen immer noch aktiv triggern, und vor allem die Querverbindungen mitgeben. Die KI berücksichtigt meinen Input und ausgewähltes internes Wissen, aber sie sieht selten von selbst, welche Abhängigkeiten zu anderen Bereichen bestehen. Perfekter, schneller Mitarbeiter, der fast alles gewissenhaft umsetzt, aber ohne den Blick über den Tellerrand.
Das ist keine Schwäche, die man wegprogrammiert. Das ist der Rahmen, den man verstehen muss, um sinnvoll einzusetzen.
Security: Grundhaltung, keine Blaupause
Security ist nicht der Fokus dieses Beitrags, aber komplett auslassen wäre unehrlich. Konkrete Architektur-Details spare ich absichtlich aus, detaillierte Beschreibungen der eigenen Verteidigungslinien erhöhen selten das Sicherheitsniveau, aber immer das Risiko. Ein paar Grundhaltungen kann ich trotzdem teilen:
Die wichtigste Entscheidung fiel am Anfang des Projekts: keine kritischen Daten auf diese Maschine. Keine Kundendaten, keine personenbezogenen Daten Dritter, keine Geschäftsgeheimnisse mit NDA. Was auf dem System liegt, sind öffentliche Studien, meine eigene Arbeit, Content-Entwürfe und meine eigenen Gedanken.
Grundprinzipien, die meiner Einschätzung nach jede vergleichbare Umgebung braucht: minimale Rechte für alle Prozesse, saubere Trennung von Code und Zustand, Aufnahme externer Inhalte nur über kontrollierte Schleusen, kontinuierliches Monitoring mit Alerts. OpenAI beschreibt für Codex ähnliche Leitplanken: klare technische Grenzen, explizite Freigaben für riskante Aktionen und Telemetrie, die nachträglich zeigt, was der Agent getan hat (OpenAI, 2026). Details dazu, und vor allem: eine ehrliche Einordnung, wo Solo-Setups an Grenzen kommen und wann externe Expertise zwingend nötig wird, gehören in Teil 3. Teil 2 ist bereits online und beschreibt die operativen Schwächen: Multi-Agent-System Schwächen.
Der wichtigste Satz vorab: Nicht anzufangen hat auch Risiken. Wer abwartet, verliert das Fenster, in dem solide Architektur mit begrenztem Risiko gebaut werden kann.
Wie viel Zeit und Geld kostet der Aufbau eines Multi-Agent-Systems?
Kurz gesagt: Das technische Fundament ist in ein bis zwei Wochen realistisch. Die echten Kosten entstehen danach: bessere Modelle, mehr Tests, mehr Monitoring und die Zeit, die Sie in Architektur statt in einzelne Prompts investieren.
Für das Fundament (Phasen 1 bis 5) brauchen Sie mit dieser Anleitung ein bis zwei Wochen. Ich habe ohne Anleitung zwei bis drei Wochen gebraucht.
Zu den Kosten sollte ich ehrlich sein: Der Einstieg liegt bei einem zweistelligen Monatsbetrag, Claude Pro oder ein vergleichbares Abo, plus einem alten Rechner und Open-Source-Software. Für ernsthafte Aufbauarbeit reicht das aber nicht lange. Meine eigene Kostenkurve spricht für sich: Februar rund 20 Euro, März bereits 90 Euro, jetzt im April fast 190 Euro. Ich bin mittlerweile im Claude Max Plan, weil die Limits mit wachsender Systemkomplexität immer wieder zur Bremse wurden. Die Abokosten der Anbieter sind in den letzten Monaten zudem deutlich gestiegen, ein Trend, der sich wahrscheinlich fortsetzt. Ich hoffe, dass der jetzige Höchststand vor allem der Aufbauphase geschuldet ist und sich in den nächsten Monaten wieder normalisiert. Wer ernsthaft damit arbeitet, sollte mit einem dreistelligen Monatsbudget rechnen, nicht mit 18 Euro.
Zur Einordnung habe ich eine KI-basierte Schätzung für den Nachbau dieses Systems durch eine externe Agentur machen lassen: rund 50.000 Euro und drei Personen. Nach zwei Monaten Praxis halte ich die Zahl für zu niedrig, realistischer wäre wohl das Zwei- bis Dreifache, wenn man Sauberkeit, Integration und Tests mitrechnet. Es ist eine grobe Schätzung, keine Marktanalyse. Was ich aber sagen kann, ohne mir auf die Schulter zu klopfen: Ich habe in meiner gesamten Berufslaufbahn noch kein Unternehmen erlebt, das in einem so engen Ausschnitt so vernetzt, automatisiert und datenbasiert arbeitet wie dieses Solo-Setup. Das liegt nicht an mir, das liegt an der Architektur und daran, dass in Unternehmen zwangsläufig andere Kräfte wirken (Rechte, Governance, Altsysteme, Abstimmung). Trotzdem: Was in diesem Korridor heute möglich ist, überrascht mich regelmäßig selbst.
Und: Das System ist nie fertig. Es wächst mit Ihnen. Jedes Problem, das mir begegnet ist, habe ich im Tandem mit Claude gelöst. Manchmal in 20 Minuten, manchmal über mehrere Wochen.
Persönlich und unromantisch: das System macht süchtig
Ein ehrliches Wort, weil ich es sonst nirgendwo gelesen habe, aber bei mir und bei fast allen Bekannten, Freundinnen und ehemaligen Kolleginnen beobachte, die ein ähnliches System bauen: Nach anfänglicher Skepsis ist man sehr schnell hooked. Ich habe die ersten Wochen fast Tag und Nacht durchgearbeitet. Nicht, weil ich musste, sondern weil es so viel Spaß gemacht hat. Vermutlich ein kontinuierlicher Dopamin-Kick, weil man komplexe Vorhaben in wenigen Minuten umsetzen kann. Und es fiel einem immer noch kurz eine weitere Sache ein, die man "nur mal eben" testen wollte.
Diese Geschwindigkeit hat eine Kehrseite. Schneller Auf- und Umbau produziert neue Fehler, die man wieder fixen muss. Und schon sitzt man im Teufelskreis und arbeitet fast nur noch am System statt mit ihm. Das ist bei mir ehrlich gesagt bis heute so. Klassischer Scope Creep. Gleichzeitig sehe ich jede dieser Stunden als Investition und als Lernen, der Effekt verblasst nicht einfach, er akkumuliert. Trotzdem: Es frisst Zeit, es ist die eleganteste Form der Prokrastination, die ich je hatte, und in Spitzenphasen habe ich meinen Wochenablauf an Token-Limits angepasst. Wer das durchzieht, sollte sich der Wirkung bewusst sein.
Der schwierigste Teil war, rückblickend, das System überhaupt rudimentär zum Laufen zu bekommen. In dieser Zeit war ich mehrfach kurz davor, alles hinzuwerfen. Das Gefühl "das wird nie funktionieren" gehört zum Aufbau dazu. Wer diese ersten Wochen übersteht, kommt auf die andere Seite, und dort ist es dann genau das erwähnte Dopamin-Feld. Zu wissen, dass diese Phase kommt und wieder geht, hätte mir damals geholfen.
Wie schnell und produktiv ist so ein System wirklich?
Kurz gesagt: Sehr schnell, aber nicht magisch. Der Engpass verschiebt sich von Umsetzung zu Auswahl, Prüfung und Steuerung: Was soll der Agent tun, woran erkennt man ein gutes Ergebnis, und wann muss ein Mensch stoppen?
Die ehrliche Antwort: schneller, als die meisten Maßstäbe zulassen. Ich ertappe mich selbst regelmäßig dabei, Aufwandsschätzungen um Faktor 50 bis 90 zu übertreiben, weil ich KI-Geschwindigkeit an menschlicher Entwicklungszeit messe. Typische neue Automatisierung oder ein Reporting-Baustein: wenige Minuten, in komplexeren Fällen 20 bis 40 Minuten, inklusive Test, Integration und Dokumentation. Die KI liest den Bestand, schreibt den Code, führt die Tests aus, dokumentiert das Ergebnis und committet. In einer Rutsche.
Die externe Validierung dafür kommt inzwischen auch aus der Forschung. Grundl, 2026 lässt drei Agentic-AI-Systeme (Claude Code Opus 4.6 und zwei GPT-5-Varianten) dieselbe kausale Ökonometrie-Analyse durchführen wie 146 akademische Teams mit überwiegend Promotionshintergrund. Ergebnis: Die Mediane liegen nah beieinander, in einem Blind-Review-Turnier werden die AI-Submissions sogar konstant vor den menschlichen Ausarbeitungen eingeordnet. Wichtiger Vorbehalt bleibt: Die Stochastik ist real, Opus 4.6 produzierte in 44 von 100 Läufen einen falschen Vorzeichen-Effekt bei der frei formulierten Aufgabe. Die Studie zeigt also beides: Das Leistungsniveau ist da, aber Mehrfachläufe und Plausibilitätschecks sind Pflicht.
In meinem eigenen Alltag heißt das: Das Bottleneck bin ich. Parallele Sessions aufsetzen, die groben Richtungen entscheiden, Querverbindungen herstellen, die KI mit den richtigen Hinweisen füttern. Ich arbeite zunehmend orchestrierend, strategisch, konzeptionell. Manche Fähigkeiten verlerne ich dadurch vermutlich, andere wachsen: das Gefühl, wann man messen muss, wann ein Ergebnis plausibel ist, wann man lieber nochmal gegenprüft.
Eine gesunde Portion Selbstkritik gehört dazu: Gerade Expertinnen verlassen sich mit zunehmender Erfahrung immer stärker blind auf KI-Output. Shaw und Nave, 2026 nennen das "cognitive surrender" und dokumentieren in Experimenten, dass Menschen auch bei fehlerhaften KI-Hinweisen häufig mitgehen. Ich kann das bei mir selbst bestätigen. Ich gebe viel Verantwortung ab und automatisiere ganze Prozessketten, meine Rolle ist in vielen Bereichen nur noch: Ideen geben, Projekte triggern, Querverbindungen herstellen, nachfragen. Das ist effizient. Aber es ist auch eine ehrliche Ansage an mich selbst, dass blinde Flecken kein Theoriethema sind, sondern ein tägliches Risiko.
Was wirklich den Unterschied gemacht hat (und was nicht)
Wenn Sie aus diesem Beitrag nur eine Sache mitnehmen sollen, dann bitte diese Liste.
Das waren aus meiner Sicht die echten Erfolgsfaktoren:
Ein starkes Modell im Terminal. Claude Code mit Opus 4.6 (und jetzt 4.7). Ohne ein leistungsfähiges Modell war jeder Versuch eine Frustrations-Übung. Schwächere Modelle verstehen große Kontexte nicht, planen schlecht und bauen Fehler ein, die man nicht sieht. Hier zu sparen kostet am Ende Wochen.
Früh anfangen, mit echten Daten, nicht mit Konzeptfolien. Keine wochenlangen Strategie-Workshops, keine KI-Framework-Tabellen, keine PowerPoint-Lenkungskreise. Mit echten, unkritischen Daten loslegen: Content-Management, Lead-Recherche, eigene Governance-Notizen. Was kritisch ist, muss jeder selbst abwägen, aber irgendwo muss man bauen, sonst lernt man nichts. Der Cisco AI Readiness Index 2024 zeigt diesen Druck gut: 85 Prozent der Unternehmen sagen, sie hätten weniger als 18 Monate für eine KI-Strategie, aber nur 13 Prozent gelten als vollständig bereit. Der Unterschied ist fast nie die Strategie, es ist das frühe Tun mit echten Prozessen. Learning by doing schlägt jedes Framework.
Ein sauberes Blackboard-Dateisystem mit Selbst-Dokumentation. Jeder Ordner hat eine README, jede Datei eine Kurzzusammenfassung für die KI, und jede Änderung wird von der KI selbst dokumentiert, inklusive Lessons Learned. Wer das auslässt, baut blind. Wer es konsequent pflegt, bekommt ein System, das über Monate hinweg besser wird statt schlechter.
Eine zentrale Datenbank von Tag eins. SQLite, ein Schema, eine Wahrheitsquelle. Nicht sechs JSON-Dateien, die niemand in Beziehung setzen kann. Die Datenbank ist das Rückgrat für jedes Reporting, jede Analyse und jede Automatisierung.
Skills, die laufend gemessen und verbessert werden. Wiederverwendbare, eng geschnittene Arbeitsabläufe statt Universal-Prompts. Messung pro Ausführung, Regressionsschutz bei Änderungen, Versionierung in Git. Ein Skill, ein Zweck.
Wissenschaftliche Methodik, intern und in der Recherche. Jede Analyse läuft durch ein festes Raster (Behauptung, Beleg, Konfidenz, Steel Man). Jede Zahl kommt aus einer Evidenz-Datenbank mit Konfidenz-Stufen. Bei wichtigen Fragen werden mehrere unabhängige Studien geprüft, nicht eine selektiv zitiert. Das schützt vor dem einfachsten Fehler: der KI zu glauben, weil sie überzeugend klingt.
Prozesse end-to-end automatisieren, der Mensch hält sich raus, aber überwacht. Ich bin das Bottleneck, nicht die KI. Je mehr Schritte ich in einer Kette selbst machen muss, desto langsamer läuft das Ganze. Gefühlt wird das System immer dann am besten, wenn ich mich am meisten raushalte. Aber: das bedeutet nicht weglaufen. Dashboards, Alerts, Qualitäts-Gates vor Veröffentlichung, regelmäßiges Nachsehen bleiben Pflicht. Autonomie ohne Überwachung ist Leichtsinn, Überwachung ohne Autonomie ist Mikromanagement. Beides braucht es.
Git für alles. Jede Änderung ist nachvollziehbar, jede Version wiederherstellbar. Das ist nicht Infrastruktur, das ist Überlebensversicherung.
Ein Fehler-Gedächtnis. Dokumentierte Fehlermuster, die der Agent abfragt, bevor er einen Fehler wiederholt. Das System wird nur klug, wenn es aus seinen Fehlern strukturell lernt, nicht nur im Nachhinein "schon mal gesehen" denkt.
Der Mensch als Strategie-Filter. Die KI schlägt vor, führt aus, dokumentiert. Die Strategie, die Querverbindungen und die Freigaben kommen von mir. Das System wird schlagartig schwach, wenn man diesen Punkt delegiert.
Das würde ich ausdrücklich nicht empfehlen:
Günstige oder schwächere KI-Modelle. Was an Abokosten gespart wird, zahlt man in Debugging-Zeit und schlechteren Ergebnissen mehrfach zurück. Ein kleines Modell mag für einfache Lookups reichen, aber nicht für Architekturarbeit.
Tipps und Tricks aus Reddit-Foren oder YouTube-"Power-Prompts". Die meisten stammen aus 2024, sind veraltet, oft sogar kontraproduktiv. Meine Empfehlung: aktuelle Primärquellen (Hersteller-Dokumentation, peer-reviewed Paper von 2025/2026, strukturierte Erfahrungsberichte erfahrener Nutzer). Die Halbwertszeit von Tutorials in diesem Feld beträgt Wochen.
Gefrickel mit dutzenden Agenten in Telegram, Discord-Bots oder bunten Orchestrierungs-Frameworks. Das sieht beeindruckend aus, produziert aber Token-Kosten, Komplexität und Angriffsfläche ohne echten Mehrwert. Ich habe selbst ein solches Agenten-Framework mehrere Wochen parallel betrieben und letzte Woche bewusst zurückgebaut. Die Gründe in Kurzform: spürbar höherer Token-Verbrauch pro Aufgabe, kleinerer nutzbarer Kontext, umständliches Debugging ohne Terminal-Werkzeuge, zusätzliche Betriebs- und Angriffsfläche, und am Ende: in keinem einzigen Anwendungsfall besser als das Terminal-Setup. Für ein Solo-System gilt: weniger Infrastruktur ist sicherer und produktiver als eine beeindruckend klingende Agenten-Topologie.
Lange Konzeptionsphase vor dem ersten echten Durchlauf. Wer erst wochenlang plant, hat wochenlang nicht gelernt. In Unternehmen braucht es vielleicht ein, zwei Zusatzschleifen für Governance, aber niemand lernt durch Theorie, wie sich ein Multi-Agent-System anfühlt. Mein Rat: mit dem unkritischsten echten Prozess starten, nach jeder Woche ehrlich bewerten, was Mehrwert bringt und was nicht.
Zu früh automatisieren. Erst muss ein Prozess fünf- bis zehnmal manuell gelaufen sein, bevor er einen Cron-Job verdient. Sonst automatisiert man Müll auf Autopilot.
Hardcoding und Schatten-Konfiguration. Pfade in Skripten, Secrets im Repo, Konfigurationen nur im Kopf. Alles, was nicht als Code oder Dokument existiert, verschwindet unter Arbeitsdruck.
Runtime-Daten und Code im selben Verzeichnis. Live-Datenbanken, Logs und Backups gehören strukturell getrennt vom Code-Repository. Wer die Trennung sauber zieht, schließt eine ganze Klasse von Unfällen strukturell aus.
Blindes Vertrauen bei allem, was nach außen geht. Intern vertraue ich den KI-Outputs weitreichend, das System hat sich diesen Kredit über Wochen erarbeitet. Aber sobald eine Aussage öffentlich wird (LinkedIn-Post, Blogbeitrag, Kundenkonzept), prüfe ich selbst nach. Und mir fallen auch nach der fünften KI-Prüfschleife noch Fehler auf. Das passt zu Studien über KI-Nutzung und Selbstüberschätzung: KI verbessert Leistung, kann aber zugleich das Vertrauen in die eigene Antwort stärker erhöhen als die tatsächliche Qualität. Wer hier nicht gegensteuert, wird schneller mit mehr Überzeugung mehr falsche Dinge sagen.
Wer diese zehn Dinge konsequent macht und die acht vermeidet, hat den Großteil der Wegstrecke geschafft. Der Rest ist Geduld und tägliche Anwendung.
Was in Teil 2 vertieft wird: Der zweite Teil ist inzwischen online und behandelt die Schattenseite: konkrete Anfängerfehler, Sycophantie, Halluzinationen, Token-Kostendynamik und Agent-Autonomie-Drift. Wer nach diesem Aufbau-Teil ernsthaft weiterdenkt, sollte ihn direkt danach lesen: Multi-Agent-System Schwächen: 5 Anfänger-Fehler und 5 belegte Risiken.
Teil 3 folgt: Dort geht es um Security, Grenzen und die Frage, wann ein Solo-Setup zwingend externe Prüfung braucht.
In Planung: Live-Webinar. In den nächsten Wochen zeige ich dieses System live, aus dem Terminal heraus, mit echten Beispielen. Keine Folien-Show, sondern die tatsächliche Arbeitsweise. Wer Interesse hat, trägt sich am besten unter der untenstehenden Mailadresse vorab ein, dann gebe ich den Termin rechtzeitig bekannt.
Fehler gefunden? Bessere Quelle? Widerspruch? Ich pflege diesen Beitrag aktiv, schreiben Sie mir direkt: marcus.machon@nous-works.de. Fragen auch gern in den Kommentaren, ich antworte.
Über den Autor: Marcus Machon berät mittelständische Unternehmen bei Microsoft 365 Governance, SharePoint-/Teams-Struktur, Power-Platform-Automatisierung und Copilot-/KI-Readiness.
Quellen
Anthropic (2026): Introducing Claude Opus 4.7. https://www.anthropic.com/news/claude-opus-4-7
Anthropic Red Team (2026): Claude Mythos Preview. https://red.anthropic.com/2026/mythos-preview/
Dell'Acqua et al. (2023): Navigating the Jagged Technological Frontier. Harvard Business School Working Paper 24-013. https://www.hbs.edu/faculty/Pages/item.aspx?num=64700
Bitkom Research (2026): Digitalisierung der Wirtschaft: Fast jedes Unternehmen beschäftigt sich mit KI. https://bitkom-research.de/news/digitalisierung-der-wirtschaft-fast-jedes-unternehmen-beschaeftigt-sich-mit-ki
KfW Research (2026): Künstliche Intelligenz kommt im Mittelstand immer häufiger zum Einsatz. https://www.kfw.de/%C3%9Cber-die-KfW/Newsroom/Aktuelles/Pressemitteilungen-Details_880896.html
Cisco (2024): AI Readiness Index. https://www.cisco.com/c/m/en_us/solutions/ai/readiness-index/archive/2024-m11.html
Shaw & Nave (2026): Thinking-Fast, Slow, and Artificial. SSRN. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6097646
Grundl (2026): A Comparison of Agentic AI Systems and Human Economists. https://claude-code-economist.com/
Google Research (2026): Towards a science of scaling agent systems. https://research.google/blog/towards-a-science-of-scaling-agent-systems-when-and-why-agent-systems-work/
Anthropic Engineering (2024): Building effective agents. https://www.anthropic.com/engineering/building-effective-agents
Anthropic Engineering (2025): How we built our multi-agent research system. https://www.anthropic.com/engineering/multi-agent-research-system
Anthropic Engineering (2026): Demystifying evals for AI agents. https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
Cemri et al. (2025): Why Do Multi-Agent LLM Systems Fail? MAST. https://arxiv.org/abs/2503.13657
Wang & Chen (2025): MIRIX: Multi-Agent Memory System for LLM-Based Agents. https://arxiv.org/abs/2507.07957
Zhang et al. (2025): Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models.
OpenAI (2026): Running Codex safely at OpenAI. https://openai.com/index/running-codex-safely/


