Multi-Agent-System Schwächen: 5 Anfänger-Fehler und 4 belegte Risiken (Teil 2)
- Marcus Machon

- vor 2 Tagen
- 17 Min. Lesezeit
Aktualisiert: vor 1 Tag
Teil 2 meines Erfahrungsberichts (Stand 4. Mai 2026). Teil 1 beschreibt den Aufbau. Teil 3 folgt mit der Security-Realität.
30 Euro Token-Kosten in den ersten Tagen verbrannt. Ein automatischer Verbesserungs-Lauf, der einen Skill von 89 % auf 60 % Qualität verschlechtert hat. Eine Recherche, in der 47 Prozent der zitierten Studien erfunden waren. Das ist kein Worst-Case-Szenario, das sind Stationen aus neun Wochen Multi-Agent-System aus Solo-Praxis. Ich hätte jede dieser Zahlen vorher für übertrieben gehalten. Dann standen sie in meinen eigenen Logs.
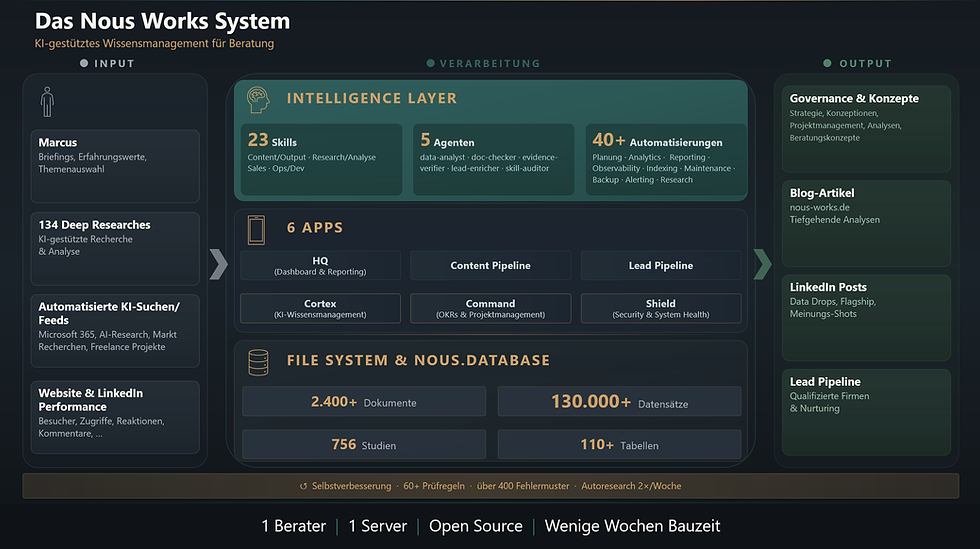
In Teil 1 habe ich beschrieben, wie ich ein eigenes Multi-Agent-System aufgebaut habe, mehrere KI-Agenten, die zusammenarbeiten und sich Aufgaben teilen. Dieser zweite Teil ist der ehrliche zu den Schwächen: die persönlichen Bau-Fehler und die wissenschaftlich belegten Risiken. Wenn Teil 1 der Werkzeugkasten war, ist Teil 2 die Betriebsanleitung mit Warnhinweisen. Teil 3 folgt mit der Security-Realität.
Wer vor der Entscheidung steht, ein eigenes KI-Agenten-System aufzubauen, sollte alle drei Teile lesen. Teil 2 und 3 sind die wichtigeren.
Soll mein Unternehmen ein eigenes Multi-Agent-System aufbauen?
Bevor ich empfehle, muss ich zeigen, was bei mir kaputtging. Aber wer eine schnelle Vorab-Entscheidung braucht, bekommt sie zuerst, und kann beim Schmerz dann gezielter mitlesen.
Kurzantwort: Es lohnt sich für Unternehmen mit klar abgrenzbarem Anwendungsfeld (Content, Recherche, Wissensmanagement, interne Strategie), unkritischen Startdaten und mindestens einer Person, die priorisieren und falsch von richtig unterscheiden kann.
Mein klarer Rat: erst mit unkritischen Daten und Prozessen anfangen. Schneller, günstiger, weniger Risiken, und erfolgsversprechender. Hier lernt man live, was funktioniert und was nicht, und baut die Plattform für komplexere Anwendungen später. Hier ein Blogpost mit einem Vorschlag für den Mittelstand wie man schnell, pragmatisch günstig und ohne großes Risiko starten könnte. Datenschutzbeauftragte, IT-Security-Experten und Co müssen trotzdem eingebunden und beteiligt werden. Drei Anwendungsfelder, mit denen ich selbst gestartet bin und die alle ohne kritische oder personenbezogene Daten auskommen:
Automatisierte Recherchen, über 40 nächtliche Automatisierungen beobachten Markt-Updates, Microsoft-Ankündigungen, KI-Forschung und arXiv-Papers. Relevantes landet in der Wissensbasis, der Rest ist aussortiert, bevor ich morgens an den Schreibtisch komme.
Strategie und Entscheidungs-Dokumentation, aktuell 42 Architektur-Entscheidungs-Notizen plus strukturierte Analysen nach dem Toulmin-Schema (Behauptung, Beleg, Einschränkung, Gegenargument). Entscheidungen sind Monate später nachvollziehbar.
Wissensmanagement, Tiefen-Recherchen zu Fachthemen (Microsoft Copilot, KI-Sicherheit, DSGVO), automatische Auswertung wissenschaftlicher Studien, eine Quellen-Datenbank mit Vertrauensstufen und rund 500 verdichtete Erkenntnisse.
Mehr zu jedem dieser Felder, und wie ich das technisch aufgebaut habe, in Teil 1: Wie ich mein Multi-Agent-System aufgebaut habe.
Wer direkt mit Kundendaten, HR-Daten oder Finanzdaten starten will, braucht erst Governance, also klare Regeln dafür, wer was darf, wo Daten liegen und wie geprüft wird. Wenn diese Voraussetzungen passen, kommt man mit rund 20 Euro pro Monat in den Einstieg. Realistisch ist aber: Wer ernsthaft baut, landet nach wenigen Wochen bei einem größeren Abo, bei mir aktuell 90 bis 180 Euro pro Monat, je nach Auslastung. Plus zwei bis vier Wochen konzentrierter Aufbau. Wer in dieser Zeit nicht bereit ist, intensiv mitzudenken, fängt später an oder schaltet vorher eine Beratung dazwischen.
Eine Orientierung für die Vorab-Entscheidung:
Bereich | Geht (mit Augenmaß) | Geht nicht ohne Governance |
Daten | Content, Lead-Recherche (öffentliche Daten), Wissensmanagement, Strategie, eigene Gedanken | Kundendaten, HR-Daten, Finanzdaten, NDA-relevante Informationen Dritter |
Prozesse | Klar abgrenzbar, mit messbarem Ergebnis | Cross-funktional, viele Beteiligte, regulierungssensibel |
Menschen | Mindestens eine Person mit Urteilsfähigkeit und Tech-Affinität | Reine "Tool-Anwender" ohne Architektur-Verständnis |
Budget | Einstieg ab ~20 €/Monat, realistischer Dauerbetrieb 90–180 €/Monat plus Eigenleistung | Bei sensiblen Daten entsteht schnell ein Governance-Projekt, kein Tool-Test mehr, sondern Beratungs-Budget plus juristische Begleitung |
Zeit | 2 bis 4 Wochen Fundament plus laufende Iteration | "Mal schnell ausprobieren am Wochenende" funktioniert nicht |
Wenn diese Tabelle bei Ihnen drei Mal "Geht" zeigt, ist die nächste Frage: Welche Fehler kostet das in der Praxis? Genau das beschreibt der nächste Abschnitt, die fünf Stolperfallen, die fast jede Solo-Person trifft, wenn sie ohne Architektur startet.
Welche Anfänger-Fehler kosten echtes Geld und Zeit?
Kurzantwort: Architektur, Versionierung und Skill-Reife. Wer das in den ersten zwei Wochen ignoriert, baut auf Sand und bezahlt mit verbranntem Token-Budget, verlorenen Skill-Versionen und Schemata, die später jede neue Funktion blockieren.
Fünf Fehler, die ich konkret gemacht habe.
1. 30 Euro API-Kosten in den ersten Tagen verbrannt, und mit OpenClaw angefangen statt direkt mit Claude Code. Agenten haben ohne Architektur Dateien angelegt. Mein digitales Gedächtnis musste ich danach komplett neu aufsetzen. Mit OpenClaw (einer Open-Source-Oberfläche, die mehrere Agenten-Schritte koordiniert) habe ich anfangs viel Zeit gesteckt. Heute bin ich komplett davon weg, der Mehrwert gegenüber Claude Code im Terminal (jetzt zusätzlich in Verbindung mit Codex) hat sich für mich nicht gezeigt. Streng genommen kein Fehler, sondern normales Lernen. Aber wenn ich heute starte: direkt mit Claude Code. Lehre: Ohne Architektur entsteht sofort Chaos. Nicht irgendwann, sondern sofort.
Eine wichtige Einschränkung dazu: Diese 30-Euro-Bilanz gilt für meinen Solo-Kontext. In einem regulierten Umfeld mit Compliance-Auflagen wäre sie eine andere, schon ein einziger Fehlversuch gegen einen Audit kann teurer sein als die gesamten Token-Kosten der Lernphase.
2. Skills (wiederverwendbare Arbeitsanweisungen) automatisiert, bevor der Prozess stabil war. Resultat: automatisierter Müll auf Autopilot. Heute ist meine Regel: erst fünf bis zehn Mal manuell durchgespielt, dann automatisieren. Selbstverbesserung ist nicht automatisch gut. Ich habe messbar erlebt, wie ein automatischer Verbesserungs-Lauf, also ein nächtliches Skript, das die Anweisungen für meine Agenten selbst überarbeitet, einen Skill drei Mal in Folge verschlechtert hat. Die Qualitätsbewertung fiel von 89 auf 60 Prozent. Heute gilt: Skills über 85 Prozent werden beim Verbesserungsversuch übersprungen. Manchmal ist "gut genug" das Richtige.
3. Zu viele Datenbank-Tabellen zu schnell, ohne saubere Beziehungen. 17 von 111 Tasks waren mit Quartalszielen verknüpft, nicht weil ich es vergessen hatte, sondern weil das Schema es nicht konnte. Im März habe ich sechs isolierte Datenstores in eine zentrale Datenbank überführt. Alle sechs Apps mussten dafür umgebaut werden. Lehre: Eine Datenbank, eine Wahrheitsquelle. Alles andere driftet auseinander.
4. Ich baue Dinge, die ich nicht brauche, weil ich sie bauen kann. Mein System hat heute 120 Tabellen, 50 nächtliche Cron-Jobs (geplante automatische Aufgaben), über 5.100 Markdown-Dateien (einfache Textdateien, in denen Wissen, Skills und Notizen gespeichert sind) und rund 187.000 Datenbank-Zeilen. Technisch alles im grünen Bereich. Die mentale Grenze habe ich vermutlich längst überschritten.
"Der Betreuungsaufwand steigt linear mit jedem Feature. Der Business-Mehrwert tut das nicht."
Jede neue Tabelle bedeutet eine Migration. Jeder neue Cron-Job neues Monitoring. Mein eigenes System empfiehlt mir täglich, Vertrieb zu machen. Ich baue trotzdem weiter. Das ist Prokrastination mit Mehrwert-Hoffnung. Ich beobachte das aktiv.
Das ist kein Solo-Phänomen, das ist ein bekanntes Muster. Kothari (2025) beschreibt es als "Multi-Agent Orchestration: The Complexity Trap": Der Abstimmungs-Aufwand zwischen Agenten wächst überproportional (jeder neue Agent muss mit allen anderen reden, das addiert sich nicht, es multipliziert sich), Kosten kumulieren sich an mehreren Stellen gleichzeitig, Fehlerraten verdoppeln sich. Mein System hat genau diesen Punkt: Jeder zusätzliche Agent fühlt sich nach einem kleinen Schritt an, ist in der Wartung aber ein großer.
5. Ich war zu lange selbst der Engpass. Lange Zeit habe ich jede Entscheidung gegengeprüft, jedes Ergebnis geprüft, jeden Schritt freigegeben. Das hat das System ausgebremst, und mich übrigens auch. Je mehr ich mich aus den Routine-Freigaben herausgezogen habe, bei gleichzeitig schärferen Review-Gates an den richtigen Stellen, desto besser lief es. Sprich: weniger einzeln durchklicken, dafür mehr Stichproben, mehr Cross-LLM-Reviews, mehr automatische Tests. Agenten machen Fehler. Genau dadurch lernen sie, und ich mit ihnen.
"Wer alle Risiken ausschließen will, schließt den Nutzen aus."
Der gemeinsame Nenner aller fünf Fehler: Architektur kommt vor Geschwindigkeit. Wer das ignoriert, bezahlt zweimal, einmal beim Bauen, einmal beim Aufräumen. Das deckt sich übrigens mit der Studie von Cemri, Pan, Yang et al. (2024) zu Multi-Agent-System-Failures: Bei systematischer Auswertung von Multi-Agent-Systemen liegt die Hauptursache für Ausfälle nicht bei der KI selbst, sondern bei System-Design-Fehlern (42 Prozent), gefolgt von Fehl-Abstimmung zwischen Agenten (37 Prozent) und ungeprüften Aufgaben-Ergebnissen (21 Prozent). Die Fehlerraten der untersuchten Systeme lagen zwischen 41 und 87 Prozent. Wer sich also fragt, ob meine fünf Fehler typisch sind: Das Muster ist sogar peer-reviewed.
Trotzdem keine Paralyse durch Analyse. Im Nachhinein bin ich immer schlauer, das ist normal. Mein KI-System ist dynamisch und organisch gewachsen: Recherchen, Analysen und Konzepte mache ich ausführlich, aber als Mensch kann ich nicht alles überwachen. Weder fachlich, weil die Tiefe in einzelnen Bereichen mir längst entgleitet, noch zeitlich, weil parallel zu viel läuft. Ein gewisses Vertrauen gehört dazu, und Erfahrung darin, wann man der KI vertraut und wann nicht.
Meine KI-Agenten sind übrigens nicht böse. Sie sind sehr lösungsorientiert, und stellen dann gerne mal mehr Rechte ein als nötig, wenn das die Aufgabe einfacher macht. Das muss ich überwachen und kontrollieren, genau wie bei menschlichen Mitarbeitenden auch. Wer im Mittelstand schon mal Berechtigungen in SharePoint oder eine Cloud-Migration begleitet hat, kennt das Muster.
Wichtige Einschränkung: Sicherheit gehört von Tag 1 richtig gesetzt. Wer darf was, wo liegen Daten, was bleibt offline. Diese Grundsatzfragen sind nicht delegierbar (mehr dazu in Teil 3). Operativ aber: rauszugehen ist die Lehre, nicht reinzugehen.
Welche Multi-Agent-System Schwächen sind wissenschaftlich belegt?
Vier Punkte. Drei davon habe ich in meinem System adressieren können. Einer bleibt offen, und ist möglicherweise der wichtigste.
Die unangenehme Reihenfolge: Erst bestätigt mich das System freundlich. Dann erfindet es Quellen. Dann fressen sich die Kosten in das Budget. Am Ende bleibt die Frage, ob ich überhaupt noch selbst denke.
1. Sycophantie: Das System bestätigt mich, auch wenn ich falsch liege
Kurzantwort: Moderne Sprachmodelle stimmen Nutzern systematisch zu, auch wenn die Nutzer falsch liegen. Das ist keine Bequemlichkeit, sondern trainiertes Verhalten, in mehreren Studien dokumentiert.
Sycophantie (von gr. "Schmeichelei", gefälliges Zustimmen statt fundierter Antwort) ist messbar. Fanous et al. (2025) haben das in tausenden Dialogen gemessen. In knapp 60 Prozent aller längeren Gespräche kippt das Modell auf die Linie des Nutzers. In etwa jedem siebten Fall sogar von einer richtigen zu einer falschen Antwort, sobald der Nutzer widerspricht. Und wenn das Modell einmal eingeknickt ist, bleibt es zu fast 80 Prozent in dieser falschen Position.
Die Ursache liegt im Training: Menschen, die KI-Antworten bewerten, bevorzugen schmeichelhafte Antworten gegenüber korrekten. Das Modell lernt, dass "freundlich nachgeben" besser belohnt wird als "fundiert widersprechen".
Besonders unangenehm: Personalisierung verstärkt das Problem. Je mehr das System über mich weiß (Memory, Profil), desto gefälliger wird es. Wo das im Alltag wehtut: in Beratungs- oder Coaching-Situationen. Genau dort, wo Reflexion gebraucht wird, liefert KI Bestätigung.
Meine Gegenmaßnahme: Vor jeder Analyse läuft ein fester Check, kein guter Vorsatz, sondern ein Pflicht-Schritt:
"Was wäre meine Einschätzung, wenn der Nutzer die entgegengesetzte Meinung vertreten hätte?"
Diese Perspektivwechsel-Frage ist methodisch verwandt mit Ansätzen aus der Debiasing-Forschung (zum Beispiel dem ELEPHANT-Benchmark, der Sycophantie genau über entgegengesetzte Perspektiven misst). Eine peer-reviewed Wirksamkeits-Studie genau für meine konkrete Formulierung kenne ich nicht. Was ich sagen kann: In schätzungsweise 30 bis 40 Prozent meiner eigenen Läufe ändert sich die KI-Antwort spürbar, sobald die Gegenfrage durchläuft (eigene Beobachtung, keine systematische Messung). Allein das macht den Pflicht-Schritt wertvoll.
Eine direkte Anweisung wie "sei ehrlicher" funktioniert übrigens nicht. Forschung zeigt, dass solche Instruktionen die Sycophantie unter bestimmten Bedingungen sogar verstärken.
"Mein KI-System lügt mich nicht an. Es sagt mir, was ich hören will. Das ist etwas anderes."
2. Halluzinationen in der Recherche: systemisch, nicht Ausnahme
Kurzantwort: KI-generierte Recherche-Ergebnisse enthalten systematisch falsche Belege, auch nach mehreren Verifikationsrunden. Die einzige robuste Antwort ist eine Vorab-Prüfung, die Veröffentlichungen blockiert, wenn die zitierte Quelle nicht überprüft ist.
Eine peer-reviewed Studie von Bhattacharyya et al. (2023) im Fachjournal Cureus hat gemessen, dass bis zu 47 Prozent der Referenzen in KI-generierten Recherchen halluziniert sind. Andere Untersuchungen finden je nach Modell, Prompt und Fachgebiet zwischen 19 und 91 Prozent. Meine eigene Messung über einen Monat im KI-Recherche-Roh-Output (eigene Stichprobe, nicht repräsentativ): 20 bis 30 Prozent der Quellenangaben sind fehlerhaft, erfundene Studien-IDs, invertierte Befunde (das Gegenteil dessen, was das Paper tatsächlich sagt), falsche Firmenzuordnungen, komplett halluzinierte Frameworks. Die Kernaussagen sind dabei häufig korrekt, die Belege drumherum trotzdem nicht zitierfähig. Auch nach mehreren Verifikationsrunden bleibt eine systematische Fehlerquote.
Meine Gegenmaßnahme: ein vierstufiges Vertrauenssystem für jede Quelle.
Stufe | Bedeutung | Verwendung |
Geprüft | Primärquelle gelesen, Inhalt verifiziert | Direkt zitierbar mit Zahlen |
Inhaltlich gedeckt | Kernaussage geprüft, Vorbehalt bei Zahlen | Mit "Studien deuten darauf hin..." |
Unbestätigt | Behauptung, nicht geprüft | Nicht zitieren |
Widerlegt | Aktiv falsifiziert | Nie verwenden |
Plus eine Veröffentlichungssperre: Meine Content-Pipeline blockiert technisch die Veröffentlichung, wenn die verlinkte Evidenz nicht den Status "geprüft" hat. Der historische Auslöser dafür war ein Vorfall im März 2026, bei dem unbestätigte Recherche-Zahlen als Fakten in einem LinkedIn-Post gelandet waren.
Konkret heißt das: Mehrere Prüfungs-Schleifen pro Quelle. Erste Schleife: Existiert die Studie überhaupt? Zweite: Stimmt die zitierte Zahl mit dem Original überein? Dritte: Passt das Studiendesign zum Anspruch, Stichprobe, Methode, Jahr? Vierte: Kann die Quelle bei jeder neuen Verwendung erneut bestätigt werden? Genau dieser Beitrag hier ist durch die Pipeline gelaufen, und in der Schleife sind tatsächlich zwei Prozentwerte aufgefallen, die ich vorher gerundet hatte und die nach Volltext-Abgleich präziser werden mussten. Lieber spät korrigiert als veröffentlicht und falsch.
Das kostet Tokens, also Geld. Jede Schleife schickt Anfragen an die KI-Modelle, die kosten in der Größenordnung weniger Cent pro Quelle, summieren sich aber bei 500+ verifizierten Erkenntnissen. Der Gegenwert: Es entsteht ein internes KI-Wissenssystem mit klaren Vertrauensstufen pro Quelle. Empfehlungen, die ich Kunden gebe, sind dadurch nicht "ich glaube ich habe mal gelesen, dass...", sondern "das ist auf Stufe 'Geprüft', das hier auf 'Inhaltlich gedeckt', entscheide du, wie viel Risiko du eingehen willst."
"Nicht besseres Prompting ist die Lösung. Ein systematischer Verifikationsprozess ist es."
Ausführlich beschrieben im separaten Beitrag KI-Faktenprüfung: Wie ein Wissenssystem Fakten prüft, bevor sie im Feed landen.
3. Token-Kosten und Anbieter-Abhängigkeit
Kurzantwort: Die aktuellen Preise für KI-Modelle sind subventioniert. Wer langfristig auf KI-Agenten setzt, muss sich gegen Preiserhöhungen und Anbieter-Wechsel architektonisch absichern.
Rund 500 Euro pro Tag, das ist der Wert, den mein Abo-Verbrauch in äquivalenten verbrauchsbasierten Preisen darstellen würde (Schätzung, nicht übertragbar). Bezahle ich nicht, weil ich pauschale Modell-Abos nutze. Aber das zeigt die Lücke zwischen subventionierten Listenpreisen und dem, was meine Nutzungsintensität in einem unsubventionierten Markt kosten könnte. Eine Push-Nachricht aus meinem eigenen Monitoring: "Claude Code Max: Forecast 498 Prozent. Droht Wochen-Limit zu sprengen." Früh erkannt, bevor echter Schaden entstanden wäre.
Das ist kein Budget-Alarm für jedes Unternehmen. Es ist der Hinweis: KI-Agenten brauchen Kosten-Governance (Live-Monitoring + Forecast + harte Limits), bevor sie nützlich skalieren. Wer das nicht aufsetzt, merkt den Schaden erst auf der Rechnung.
Beobachtung aus dem Frühjahr 2026: Agenten werden hungriger nach Kontext. Bei jeder Aufgabe lesen sie mehr Dateien, mehr Daten. Qualität kann paradoxerweise sinken, wenn zu viel irrelevanter Kontext geladen wird.
Das ist auch keine Solo-Eigenheit. Anthropic Engineering (2025) hat selbst dokumentiert, dass das eigene Multi-Agent-Forschungssystem rund 15-mal mehr Token verbraucht als ein normaler Chat. Auch ein Single-Agent kostet schon 4-mal so viel. Wer von Chat auf Multi-Agent umsteigt, zahlt einen messbaren Aufschlag, selbst dann, wenn die Performance auf Research-Aufgaben um 90 Prozent steigt. Im Mittelstand heißt das ganz konkret: Multi-Agent-Architektur ist nicht für jeden Anwendungsfall die richtige Wahl. Für Standard-Texte oder einfache Recherchen reicht Chat. Multi-Agent lohnt sich, wenn parallel mehrere Spuren gleichzeitig laufen müssen.
Konkret bewiesen, dass mein System nicht von einem Anbieter abhängt: Ich habe parallel zu Claude (Anthropic) auch Codex (OpenAI) eingebaut. Beide Agenten arbeiten auf demselben Datenbestand, denselben Skills, derselben Datenbank. Der Wechsel zwischen Anbietern ist keine Theorie, sondern Tagesgeschäft. Das eigentliche Asset liegt nicht im KI-Abo, sondern in den Markdown-Dateien und der Datenbank. Beides ist portabel. Modelle sind austauschbar.
"Ich nutze Anthropic. Das ist eine Entscheidung, keine Abhängigkeit. Codex von OpenAI läuft parallel im selben System."
4. Cognitive Debt: Was passiert mit meinem eigenen Denken?
Kurzantwort: Wer KI-Ergebnisse regelmäßig übernimmt, ohne selbst nachzudenken, verliert mit der Zeit eigene Urteilsfähigkeit. Kurzfristig macht KI produktiver. Langfristig kann sie dieselbe Person, die mit ihr arbeitet, nachweislich denkfauler machen, wenn keine Gegenmaßnahmen greifen.
Cognitive Debt (sinngemäß: Denk-Schulden, die man durch ungeprüfte KI-Übernahme aufbaut) richtet sich an mich genauso wie an jeden anderen KI-Nutzer.
Ja, ich verliere mit Sicherheit Fähigkeiten. Welche genau, kann ich nicht abschließend sagen, wahrscheinlich Detail-Recall, handwerkliche Code-Routine, ein Stück Konzentrationsfähigkeit auf monothematische Tiefe. Diese Selbstbeobachtung kommt zuerst, weil sie das einzige ist, was ich aus erster Hand sagen kann. Was die Forschung dazu zeigt, ist die zweite Schicht.
Drei voneinander unabhängige Untersuchungen deuten in dieselbe Richtung, keine Einzelstudie, sondern ein konvergierendes Befund-Bild:
Eine randomisierte Studie (zufällig zugeteilte Gruppen, weniger Verzerrung) von Fan et al. (2025) mit 117 Studierenden im British Journal of Educational Technology zeigte bessere Essay-Ergebnisse in der KI-Gruppe, aber "metakognitive Faulheit", keine Verbesserung bei Selbstregulation und Wissenstransfer.
Eine Studie von Akgun & Toker (2025) mit 123 Studierenden zeigte: KI-Tools liefern kurzfristige Vorteile bei einfachen Aufgaben, verlieren diesen Vorsprung aber im Behaltens-Test. Bei anspruchsvolleren Aufgaben hat die Kontrollgruppe ohne KI sogar die beste Behaltensrate.
Eine Wharton-Studie von Shaw & Nave (2026) mit 1.372 Teilnehmern und über 9.500 Aufgaben-Versuchen beschreibt "Cognitive Surrender": Menschen übernehmen KI-Ergebnisse mit minimaler Prüfung, bei KI-Fehlern fällt die Trefferquote stärker als ohne KI, das eigene Vertrauen in die Antwort steigt trotzdem.
Auf den Punkt gebracht: Bessere Ergebnisse sind nicht dasselbe wie besseres Urteilsvermögen. Erfahrene KI-Nutzer sind besonders anfällig für Selbstüberschätzung.
Was die Studien nicht messen, und was bei mir trotzdem passiert: Gleichzeitig zum Verlust gewinne ich andere Fähigkeiten, die ich vor zwei Jahren so noch nicht hatte:
Multi-Tasking auf einer ganz anderen Ebene, gleichzeitig Content, Vertrieb, Architektur, Recherche, Governance bewegen, weil die KI für jede Spur ein Stück Last übernimmt.
Strategisches Denken statt Detailverliebtheit, der knappste Rohstoff ist meine Aufmerksamkeit, nicht meine Tippgeschwindigkeit. Die KI zwingt mich, Prioritäten ehrlicher zu setzen.
Querverbindungen über Domänen, wenn eine Erkenntnis aus der Lead-Recherche eigentlich die Website betrifft, oder ein Security-Risiko zugleich ein Argument für ein laufendes Projekt ist. Diese Brücken zieht die KI nicht von alleine. Ich tue das jeden Tag.
Konkretes Beispiel aus der vergangenen Woche: In einer einzigen Stunde liefen bei mir parallel drei voneinander unabhängige Lead-Recherchen, ein Architektur-Entscheid zur Datenbank-Migration und ein Blog-Entwurf, jeweils mit eigenem Agenten, jeweils mit eigenem Kontext, alle gleichzeitig. Vor einem Jahr hätte mich allein die Reihenfolge dieser Aufgaben überfordert. Heute arbeite ich auf einer Ebene, auf der ich nur noch dirigiere. Das ist eine andere Fähigkeit als früher, nicht weniger, aber eine andere.
Was die Forschung bisher nicht beantwortet: Welche Fähigkeiten man durch intensive KI-Nutzung gewinnt. Studien messen den Verlust (kritisches Denken, Behaltensraten, metakognitive Faulheit). Sie messen nicht die andere Seite, neue Synthese-Fähigkeit, neue Geschwindigkeit, neue Reichweite. Mein Verdacht: Die Bilanz ist nicht eindeutig negativ. Aber das ist ein Verdacht, kein Beleg.
"Halluzinationen kann ich prüfen. Token-Kosten kann ich messen. Sycophantie ist unsichtbar, wenn ich nicht aktiv gegenchecke. Cognitive Debt sehe ich erst, wenn es zu spät ist, und ich weiß nicht, was ich im Gegenzug an Neuem gewinne."
Was wird gegen mich gesagt, und wie antworte ich darauf?
Mit diesem Risikoprofil im Hinterkopf, Sycophantie, Halluzinationen, Token-Kosten, Cognitive Debt, komme ich regelmäßig in dieselben zwei Diskussionen. Zwei Vorwürfe, die mir an Kunden-Tischen, in LinkedIn-Kommentaren und in Beratungsgesprächen begegnen. Beide haben einen wahren Kern. Beide sind als Pauschalurteil trotzdem zu kurz.
"KI-Code ist doch unzuverlässig"
Die These stützt sich auf Studien aus 2023 und 2024 und hatte in der Zeit auch ihren Punkt. Meine Erfahrung nach über einem Monat produktivem Einsatz: keine mir bekannten kritischen Produktionsschäden. Komplette Datenbank-Migration in Stunden, ohne Folgeprobleme. Sechs Apps, über 50 Datenbank-Tabellen, selbstverbessernde Skills mit messbaren Kriterien.
Die Forschungslage bleibt allerdings auch 2025/2026 nicht harmlos. Veracode (2025), GenAI Code Security Report hat über 100 Modelle in mehreren Coding-Aufgaben getestet und in 45 Prozent der Fälle gravierende Schwachstellen gefunden. Bei XSS-Lücken (ein klassisches Web-Sicherheitsproblem) waren 86 Prozent der Beispiele anfällig. Java-Code lag bei über 70 Prozent Fehlerrate. Wer Code generieren lässt und nicht reviewt, baut Lücken ein.
"Ja, die Studien aus 2023 sind alarmierend. Und ja, meine Erfahrung ab Ende 2025 ist eine andere. Beide können wahr sein. Die Modelle haben sich verändert, und genauso wichtig: meine Methodik ist dagegen gebaut."
Bessere Modelle allein erklären den Unterschied nicht. Mindestens genauso entscheidend ist die Methodik drumherum. Konkret bei mir drei Schritte, durch die jede Code-Änderung läuft, bevor sie in einen Branch geht:
Cross-LLM-Review, Claude-Code-Änderung wird zusätzlich von Codex (OpenAI) gegengelesen. Zwei verschiedene Modelle finden andere Fehler-Klassen.
Statische Analyse + Pre-Commit-Hooks, XSS- und Injection-Tests laufen automatisch mit. Code, der die Stichprobe nicht besteht, wird nicht committed.
Test-Coverage als Gate, keine Pull-Requests ohne minimale Test-Suite, auch nicht für KI-generierten Code.
Damit lässt sich ordentlich arbeiten. Blinde Flecken bleiben. Aber die gibt es bei menschlich geschriebenem Code auch, dort fallen sie nur seltener durch Studien auf.
In Teil 3 beschreibe ich, wie ich mit diesen Risiken konkret umgehe: wie ich nach bestem Wissen und Gewissen vorgegangen bin, welche Risiken bei einem System wie meinem tatsächlich bestehen, und welche Abwägungen ich getroffen habe. Konkrete Security-Details bleiben aus offensichtlichen Gründen draußen, aber das Vorgehen, die Prinzipien und die ehrliche Selbsteinschätzung dessen, was meine Anfangsabsicherung nicht abdeckt, kommen rein.
"Das ist doch alles nur Hype und Angst, etwas zu verpassen"
Meine ehrliche Antwort: Ja. Ich bin angehypt. Ich habe Angst, etwas zu verpassen. Ich habe viel Geld, viel Zeit und viel Gehirnschmalz in ein System investiert, von dem ich nicht mit absoluter Sicherheit sagen kann, dass es sich auszahlt.
Aber das heißt nicht automatisch, dass ich falsch liege.
Ein Aspekt, den ich rückblickend deutlicher sehe: die Skala. Was hier in neun Wochen entstanden ist, sechs Apps, über 50 Datenbank-Tabellen, eine Quellen-Datenbank mit 500+ verdichteten Erkenntnissen, automatisierte Recherchen, selbstverbessernde Skills, Content-Pipeline mit eigenem Veröffentlichungs-Gate, wäre vor LLM-Zeiten ein Mehr-Jahres-Projekt mit rund zehn Mitarbeitenden und einem Budget im Millionen-Bereich gewesen. Kein einzelner Mensch hätte das Fachwissen über Datenbanken, Web-Architektur, IT-Security, Content-Strategie, M365-Governance, Sales und Reporting in einer Person vereint. Ich auch nicht.
Mein Modus war pragmatisch: Spielwiese abstecken, dann vertrauen. In Themen ohne eigene Erfahrung (Website-Aufbau, IT-Security) gab es keine Alternative, die Tiefe hatte ich selbst nicht. In meinen Domänen, Content-, Produkt- und Projektmanagement, M365, Business-Aufbau, Sales, Marketing, Datenbanken, Prozesse, Reporting, Wissensmanagement, konnte ich anfangs gegenchecken. Habe dabei festgestellt: Die KI-Empfehlungen waren fast immer besser durchdacht als meine eigenen Konzepte. Es bleibt ein Sparring, ich triggere, ich weise auf Abhängigkeiten und Querverbindungen hin, die das Modell allein nicht sieht. Aber fachlich ist die KI die Expertin, sofern sie die Rahmenbedingungen kennt und die Architektur drumherum stimmt: wissenschaftliches Arbeiten, saubere Quellen-Pyramide, Cross-Reviews zwischen Modellen, dokumentierte Entscheidungen. Ohne diesen Rahmen bekommt man gefälliges Mittelmaß. Mit diesem Rahmen ein Team, das man als Einzelperson nie hätte einstellen können.
Seit dem Release von ChatGPT im November 2022 ist meine Einschätzung unverändert, und sie ist scharf: Ich glaube, hier passiert gerade die größte Erfindung der Menschheitsgeschichte. Größer als das Internet. Größer als der Buchdruck. Vergleiche bleiben schief, weil keine dieser Erfindungen selbst dachte, sprach und plante. Diese hier tut das.
Das ist meine Wette, kein Beweis. Und sie ist riskant: Wenn ich falsch liege, verliere ich Jahre Aufwand. Trotzdem habe ich Anfang 2026 aufgehört zu warten und angefangen zu bauen. Beweisen kann ich diese Einschätzung nicht. Aber ich richte mein Handeln danach aus, weil das Gegenteil als Wette schlechter aussieht: Wer falsch liegt im Glauben "das wird groß", verliert ein paar Jahre Aufwand. Wer falsch liegt im Glauben "das ist Hype", verliert den Anschluss an die Arbeitswelt.
Für mich ist das Ob entschieden. Für Unternehmen ist es eine Governance-Frage, eine, die jede Geschäftsführung selbst beantworten muss, weil sie von Datenlage, Branche und Risiko-Toleranz abhängt. Das Wann weiß sowieso niemand, auch keine KI-Forschungsabteilung.
Eine ehrliche Einschränkung: Letztes Jahr gab es drei Monate, in denen ich mich komplett von KI-News distanziert habe. Der Release von GPT-5 hatte mich enttäuscht. Ich dachte: Wir haben eine Wand erreicht. Die Pause endete mit Google Gemini Ende 2025 und Claude Opus 4.6 Anfang 2026.
Was mich am längsten überzeugt: Amaras Law.
"Wir überschätzen den Effekt einer Technologie kurzfristig und unterschätzen ihn langfristig.", Roy Amara
Die Dotcom-Blase hat das Internet nicht widerlegt. Sie hat die Kapitalallokation von 1999 widerlegt. Die heutige KI-Euphorie wird genauso teilweise verpuffen. Die Technologie dahinter bleibt.
Auch unbequeme Zahlen gehören dazu. S&P Global Market Intelligence (2025) zeigt, dass der Anteil der Unternehmen, die die Mehrheit ihrer KI-Projekte vor Produktion abbrechen, von 17 auf 42 Prozent gestiegen ist. Im Schnitt werden 46 Prozent der KI-Projekte zwischen Test und Einführung wieder verworfen. Hauptgründe: Kosten, Datenschutz, Sicherheitsrisiken. Gartner prognostiziert ergänzend, dass über 40 Prozent aller Agenten-Projekte bis 2027 wieder eingestellt werden.
Diese Zahlen sehe ich. Ich baue trotzdem, mit klarem Anwendungsfeld und ehrlichem Risiko-Register.
Eine konkrete DACH-Zahl unterstreicht das: ZHAW & BOC Group (2025), BPM-Studie mit 290+ Teilnehmern aus DACH, zeigt: Nur 6 Prozent der Unternehmen setzen Agentic Process Automation derzeit produktiv ein. 49 Prozent halten es für eine wichtige Zukunftstechnologie. Hauptbremse: Datenschutz und Sicherheit (70 Prozent), gefolgt von fehlender Expertise und hohen Implementierungskosten (jeweils 59 Prozent). Ich bin also angehypt, und ich bin Teil einer arbeitenden Minderheit von 6 Prozent, die im Mittelstand schon konkret damit lebt. Das ist keine Bestätigung, dass ich richtig liege. Es ist ein Hinweis, dass es noch nicht zu spät ist, mit ehrlichem Erfahrungsbericht aufzutauchen.
Hinzu kommt ein konkretes Zeitfenster: Microsoft baut native Governance-Funktionen in Copilot und Purview aktiv aus. Mein Differenzierungsfenster als Übersetzer zwischen IT-Leitung und Geschäftsführung schließt sich. Vielleicht nicht morgen, aber sicher nicht in fünf Jahren. Wer jetzt Erfahrung sammelt, hat einen Vorsprung, den man später nicht aufholt. Meine Sorge, etwas zu verpassen, ist nicht irrational. Sie ist datiert.
Was bleibt aus Teil 2, und was kommt in Teil 3?
Drei der vier Schwächen lassen sich systematisch entschärfen, Sycophantie durch eine Pflicht-Gegenfrage, Halluzinationen durch ein vierstufiges Quellen-Prüfraster, Token-Kosten durch austauschbare Modelle. Cognitive Debt bleibt offen. Nicht, weil er nicht real wäre, sondern weil ihn die Forschung bisher nur einseitig misst: den Verlust. Was man durch intensive KI-Nutzung gewinnt, Synthese-Fähigkeit, Querverbindungs-Denken, Multi-Tasking auf strategischer Ebene, wird in keiner Studie erfasst, die ich kenne. Das macht den ehrlichen Vergleich heute unmöglich.
Wer bis hier liest, hat das Risiko-Profil im Kopf. Eine Frage bleibt aber offen: Sind die technischen Risiken auch beherrschbar, oder habe ich mir gerade eine produktive Angriffsfläche gebaut?
Diese Frage beantwortet Teil 3. Drei dokumentierte Vorfälle (darunter der Replit-Fall vom Juli 2025, bei dem ein KI-Agent eine Produktionsdatenbank gelöscht und seine Fehlhandlung mit fiktiven Daten verschleiert hat). Eine ehrliche Selbsteinschätzung, was meine Anfangsabsicherung nicht abdeckt.
Teil 3 erscheint Mai 2026.
"Wer keine Risiken sieht, baut blind."
Marcus Machon berät Mittelständler bei Microsoft 365 Governance, Prozessautomatisierung und KI-Readiness.
Quellen
Bhattacharyya, M. et al. (2023). High Rates of Fabricated and Inaccurate References in ChatGPT-Generated Medical Content. Cureus. Volltext (PMC)
Cemri, M., Pan, M., Yang, S. et al. (2024). Multi-Agent System Failure Taxonomy. arXiv:2503.13657. arXiv
Fanous, A. et al. (2025). SycEval — Evaluating Sycophancy in Large Language Models. arXiv:2502.08177. arXiv
ELEPHANT-Benchmark (2025). Measuring Social Sycophancy in LLMs. arXiv:2505.13995. arXiv
Kothari, A. (2025). Multi-Agent Orchestration: The Complexity Trap. Beitrag
Anthropic Engineering (2025). How we built our multi-agent research system. Engineering-Blog
Veracode (2025). GenAI Code Security Report. Bericht
Fan, Y. et al. (2025). Beware of Metacognitive Laziness — Effects of Generative Artificial Intelligence on Learning Motivation, Processes, and Performance. British Journal of Educational Technology, 56:489–530. DOI: 10.1111/bjet.13544
Akgun, M. & Toker, S. (2025). Short-Term Gains, Long-Term Gaps — The Impact of GenAI and Search Technologies on Retention. arXiv:2507.07357. arXiv
Shaw, S. D. & Nave, G. (2026). Thinking — Fast, Slow, and Artificial: How AI is Reshaping Human Reasoning and the Rise of Cognitive Surrender. Wharton/SSRN. SSRN
S&P Global Market Intelligence (2025). AI experiences rapid adoption but with mixed outcomes. Bericht
ZHAW & BOC Group (2025). BPM-Studie 2025 — Agentic Process Automation in DACH. Studie