Mein automatisierter Blogprozess: Was ein Agentensystem mit Claude Code und Codex wirklich leistet
- Marcus Machon

- vor 6 Tagen
- 14 Min. Lesezeit
Aktualisiert: vor 2 Tagen
Eigenständiger Praxis-Beitrag im Zusammenhang zu Teil 1: Multi-Agent-System aufbauen und Teil 2: Multi-Agent-System Schwächen. Statt Architektur und Risiken zeige ich hier das Live-Ergebnis: ein automatisierter Blogprozess am Beispiel dieses Beitrags. Gleichzeitig ist es ein Praxisbeispiel dafür, was ein Agentensystem mit Claude Code und Codex im Mittelstand leisten kann. Teil 3 der Reihe zur Security-Realität folgt separat.
Heute früh, kurz nach zwei, habe ich einen Absatz in das Eingabefeld meiner KI getippt (in der Fachsprache „Prompt"). Mein Auftrag an das System: ein automatisierter Blogprozess soll aus diesem einen Absatz einen veröffentlichungsreifen, ausführlichen Blogbeitrag machen. Sinngemäß stand dort: „Recherchiere für einen Blogpost zu unserem End-to-End-Blogprozess. Bitte arbeite mit Infografiken. Lass Codex und das Panel draufschauen, bevor wir veröffentlichen." Die erste Rohfassung entstand in unter 60 Minuten. Was Sie jetzt lesen, ist die nachrecherchierte, redaktionell geprüfte Fassung: ein Beitrag mit Recherche, Quellen, Infografiken, einem echten Screenshot, Faktencheck und einer zweiten KI, die als unabhängiger Prüfer drübergeschaut hat.
Transparenzhinweis (Stand 28. Mai 2026): Dieser Beitrag wurde KI-gestützt erstellt. Claude Code und Codex unterstützten Recherche, Erstentwurf, SEO-/GEO-Analyse, Infografik-Konzepte, Faktencheck und Qualitätskontrolle; redaktionelle Prüfung, Verantwortung und Freigabe liegen bei mir. Art. 50 des EU AI Act gilt nach Art. 113 ab 2. August 2026 und verlangt nicht pauschal einen Hinweis für jeden KI-unterstützten Blogtext. Bei Textinhalten sieht Art. 50(4) eine Ausnahme vor, wenn menschliche Prüfung oder redaktionelle Kontrolle und klare redaktionelle Verantwortung vorliegen (Europäische Kommission, 2026). Ich kennzeichne es hier trotzdem, weil der Entstehungsprozess selbst Thema des Artikels ist.
Klingt nach Marketing-Story. Ist aber meine echte Arbeitsweise (und natürlich nur das, was mein Solo-Setup hergibt, kein Enterprise-Vergleich). Der ehrliche Punkt kommt sofort: die 60 Minuten waren nicht das Beeindruckende, beeindruckend war der Aufbau davor. Ein automatisierter Blogprozess steht und fällt nicht mit dem Tool-Stack. Tools sind eine Stunde Installation. Architektur sind zwei Monate konzentrierte Arbeit, und etwas, das ich heute noch jeden Tag weiterbaue.
Warum das relevant ist, wenn Sie ein Unternehmen mit 100 oder 300 Mitarbeitenden führen: Eine vollständig lizenzierte Copilot-Welle für 200 Mitarbeitende kostet rund 30 Euro pro Kopf und Monat, also grob 70.000 € pro Jahr. Wenn am Ende des Jahres die Hälfte der Lizenzen ungenutzt in Ihrer Microsoft-365-Umgebung liegt, weil niemand wusste, wofür, steht diese Verbrennung als echte Position in Ihrer Gewinn- und Verlustrechnung. Architektur entscheidet, ob diese Position als Investition oder als Verlust verbucht wird.
Und noch ein Punkt, der für die Glaubwürdigkeit dieses Beitrags wichtiger ist als alles andere: Bevor Sie diesen Artikel lesen konnten, hat eine zweite, unabhängige KI ihn gegengeprüft (OpenAI Codex auf Basis von GPT-5.5, also nicht das gleiche Modell, mit dem ich geschrieben habe). Das hat einen handfesten Grund: Sprachmodelle neigen messbar dazu, ihrem eigenen Autor zustimmend zu antworten. In der Fachsprache nennt man das Sycophantie, also gefälliges Zustimmen statt fundierter Antwort. Eine eigene Anleitung kann diese Tendenz nicht selbst auflösen. Eine fremde KI als Gegenprüferin dagegen schon. Das ist der wichtigste Unterschied zwischen „ich schreibe mit KI" und „ich habe einen automatisierten Blogprozess mit KI gebaut". Genau hier beginnt das, was ich intern mein Claude Code Agentensystem nenne.
Ein bewusster Hinweis zur Ehrlichkeit dieses Experiments: Bei diesem Beitrag habe ich den Prüfpfad sichtbar gemacht, den man normalerweise nicht sieht: interne Recherche, SEO-/GEO-Analyse, Faktencheck, Codex-Review, Panel-Review und am Ende meine redaktionelle Entscheidung. Ich wollte nicht zeigen, dass KI den Menschen ersetzt. Ich wollte zeigen, welche Teile eines professionellen Workflows heute schon maschinell vorbereitet werden können und an welchen Stellen Verantwortung nicht delegierbar ist.
Ja, das hat seinen Preis. Die letzte Arbeit verschwindet nicht. Bild und Text müssen zusammenpassen, Zahlen müssen gegen Quellen laufen, und manchmal muss ein Satz einfach wieder menschlicher werden. Mir sind beim Prüfen zum Beispiel kleine Inkonsistenzen aufgefallen, etwa wenn eine Zahl in einer Infografik anders steht als im Fließtext daneben. Vieles davon kann die KI vorbereiten oder auf Zuruf nachziehen. Trotzdem gehört am Ende ein menschlicher Schluss-Lese-Durchgang dazu. Der Grund ist einfach: Verantwortung verschwindet nicht im Prompt.
Was Sie in den nächsten 8 Minuten lesen:
Wie aus einem Absatz Prompt ein fertiger Blogbeitrag wird, Phase für Phase
Was Skills, Hooks und Subagenten sind, und warum sie der eigentliche Hebel sind
Wo ich noch jeden Schritt prüfe, und wo nicht mehr
Warum die Architektur bei Claude Code und Codex die wirkliche Arbeit war, nicht der Workflow
Vor allem: woran Sie erkennen, ob Ihr Unternehmen schon reif für so eine Automatisierung ist, oder erst seine Daten- und Berechtigungsbasis ordnen muss
Schnellpfad: Wenn Sie nur die Unternehmens-Implikation suchen, springen Sie direkt zu „Was das für Ihr Unternehmen heißt". Wer den Mechanismus prüfen will, liest die ersten beiden Abschnitte. Wer die Bauanleitung dahinter braucht: Teil 1 hat das System beschrieben, Teil 2 die Schwächen. Dieser Beitrag ist die operative Anwendung 😉.
Wie funktioniert ein vollautomatisierter Blogprozess mit einem Agentensystem?
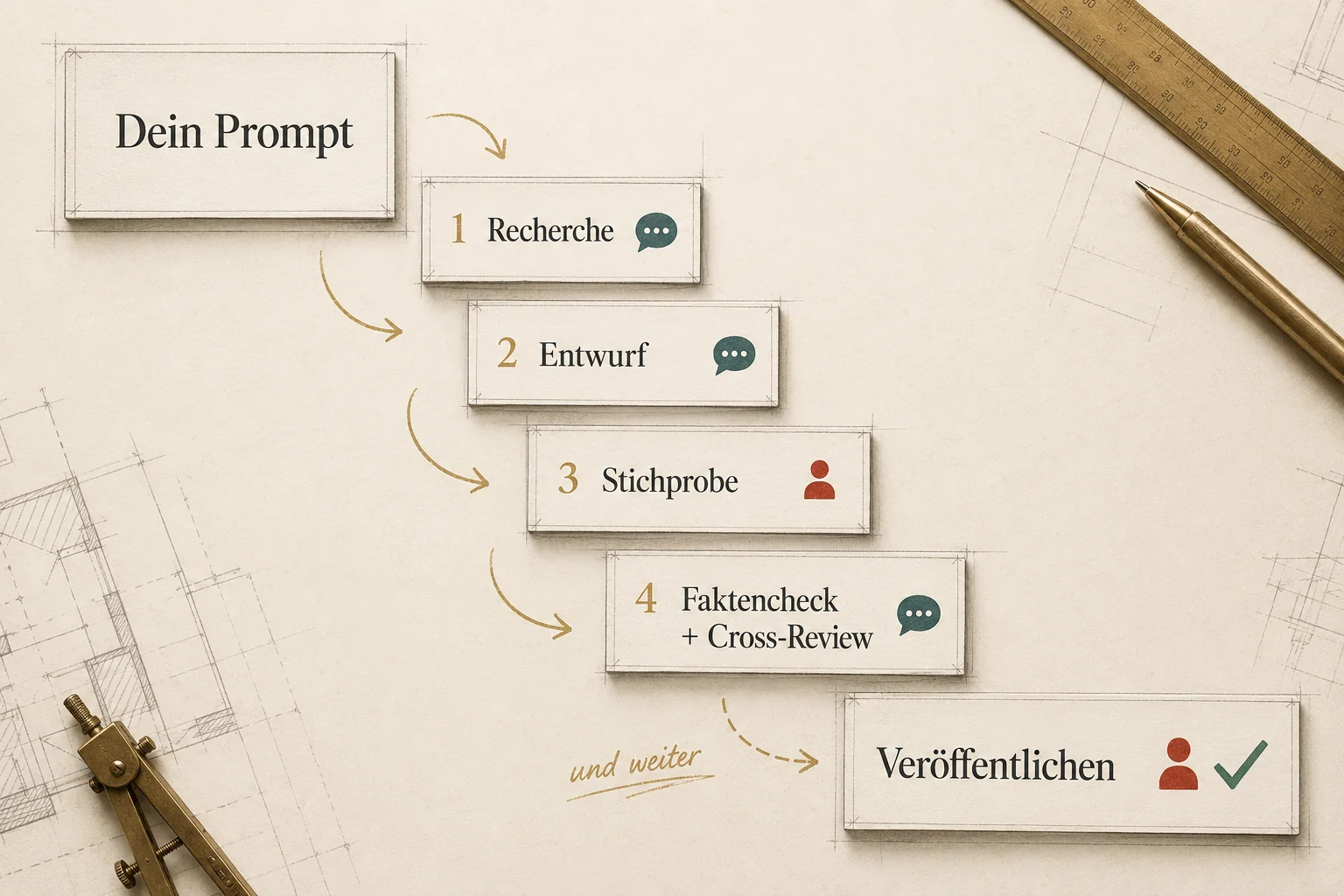
Kurzantwort: Mein Prompt hat einen Skill ausgelöst, also eine schriftliche Anleitung für die KI. Dieser Skill steuert neun Phasen vom Auftrag bis zur Veröffentlichung, mit klar definierten Übergaben zwischen KI und mir.
Ein Skill ist nichts Magisches. Am ehesten ist es die laminierte Arbeitsanweisung, die in einer gut geführten Werkstatt an der Wand hängt: „So machen wir das hier, Schritt für Schritt, und das prüfen wir, bevor etwas rausgeht." Für die KI ist so ein Skill technisch nur eine schlichte Textdatei (eine Markdown-Datei, also reiner Text mit ein paar Überschriften und Listen), in der steht: „Wenn jemand ‚blog' sagt, durchlaufe diese neun Phasen, lies vorher diese Pflicht-Dokumente, prüfe das hier, frage mich bei diesen Punkten." Mein Blog-Skill ist heute rund 220 Zeilen lang. Ohne ihn würde die KI jedes Mal bei null anfangen und neu improvisieren.
Wenn ich „lass uns einen Blogpost schreiben" sage, passiert konkret das hier:
Skill wird geladen. Die KI liest die Anleitung und die verknüpften Pflicht-Dokumente: Sprach-Stil (damit der Text nach mir klingt), Regeln für den Faktencheck, Vorgaben für Suchmaschinen-Auffindbarkeit, eine Liste typischer KI-Schreib-Muster, die zu vermeiden sind, und die Definition, wie lang so ein ausführlicher Beitrag sein soll.
Auftrags-Check. Sechs Punkte werden gleich zu Beginn geprüft: Stimme, Zielgruppe, Anlass, Beleg, Format und Beitrags-Typ. Wenn mehrere unklar sind, kommen Rückfragen. Heute habe ich „keine Rückfragen, mach mal" gesagt, also hat das System sinnvolle Standard-Annahmen gewählt und das offen gelegt.
Recherche-Phase startet automatisch. Mein internes Wissens-Wiki (Tausende verlinkte Notizen, in denen ich seit Monaten alles ablege, was ich lerne), eine Datenbank mit über tausend bereits geprüften Quellen und eine zweite Datenbank mit verdichteten Erkenntnissen aus früheren Recherchen. Seit diesem Review ist dieser Schritt ein Pflichtschritt, der nicht übersprungen werden darf: Vor Gliederung und Entwurf muss die interne Suche in meiner Belegsammlung, meinen gesammelten Erkenntnissen und meinem Wissens-Wiki sichtbar dokumentiert sein. Erst danach kommt gezielte Suche im Internet, wenn etwas fehlt.
Eine Gliederung wird vorgeschlagen, mit den Pflicht-Feldern für Suchmaschinen-Optimierung (welche Suchanfragen wir bedienen wollen, welche typischen Leserfragen).
Erstentwurf entsteht mit Quellenangaben direkt im Text, einer Kernbotschaft pro Abschnitt und einem festen Schluss-Block (Handlungs-Aufforderung, kurze Autoren-Vorstellung, Quellenliste).
Faktencheck und Stilprüfung. Jede Zahl wird gegen meine Evidenz-Datenbank verglichen. Außerdem läuft ein automatischer Durchgang, der typische KI-Schreib-Marker entfernt. Ein Beispiel sind die immer gleichen „Nicht X. Sondern Y."-Formulierungen, die sofort nach KI klingen. Dass sich KI-Texte an wiederkehrenden Mustern erkennen lassen, ist inzwischen gut untersucht: Sprachmodelle produzieren typische Eigenheiten wie Floskeln und überflüssige Erklärungen (Chakrabarty et al., 2025), und selbst sorgfältiges Glätten einzelner Formulierungen ändert die tiefer liegenden Muster auf Ebene der Textstruktur kaum, an denen ein Text als KI-generiert auffällt (Russell et al., 2026). Genau deshalb ersetzt dieser maschinelle Durchgang keinen menschlichen Schluss-Lese-Gang.
Bild-Konzepte werden geschrieben und die Infografiken entweder direkt als Prompt für ein Bildmodell eingegeben, oder als Mischung aus Bildmodell und nachträglich gesetztem Text (weil Bildmodelle deutsche Beschriftungen oft verfälschen).
Codex bekommt den Entwurf zur Zweitmeinung. Codex ist OpenAIs Programmier-Assistent, ich benutze ihn hier als unabhängige Prüf-KI auf der Grundlage von GPT-5.5.
Veröffentlichung im Content-Management-System (CMS) der Website über eine Blog-Pipeline (also ein automatisches Übersetzungs-Skript), die meine Textdatei in das Format der Website überträgt, die Schlagworte prüft und den Schluss-Block sauber einsetzt. Der „Veröffentlichen"-Button bleibt bei mir.
Take-away: Ein guter Prompt ist nichts ohne die Anleitung dahinter. Ohne Skills bleibt viel freundliche Improvisation. Mit Skills wird aus derselben KI ein wiederholbarer Prozess.
Kurzer Hinweis für eilige Entscheidende: Die nächsten beiden Abschnitte erklären die Bausteine eines Agentensystems. Wenn Sie nur die Konsequenz für Ihr Unternehmen brauchen, springen Sie zum Abschnitt „Was das für Ihr Unternehmen heißt".
Was sind Skills, Hooks und Subagenten in der Praxis?
Kurzantwort: Skills sind Anleitungen, Hooks sind automatische Auslöser („wenn X passiert, prüfe Y"), Subagenten sind Spezialisten mit eigenem Kontext. Zusammen ersetzen sie das, was in Unternehmen sonst über vier Tools, drei Abstimmungs-Meetings und eine PowerPoint verteilt ist.
Anthropic hat im Oktober 2025 das Skills-Konzept öffentlich gemacht (Anthropic 2025: Agent Skills; technische Hintergründe siehe Anthropic Engineering: Equipping agents for the real world). In meinem System nenne ich diese Schicht bewusst Agent Skills (Anthropic), weil es nicht um einzelne Eingabe-Schnipsel geht, sondern um wiederverwendbare Arbeitsanleitungen. Der Gedanke ist einfach: Wenn die KI bei der gleichen Aufgabe immer wieder ähnliche Schritte macht, schreibt man diese Schritte einmal sauber auf und lädt sie als Anleitung ein, statt sie in jeden Prompt zu kopieren. Ich habe heute über zwei Dutzend solche Skills im Einsatz, von /blog (dieser hier) bis /fact-check, /leads, /triage (Posteingang verarbeiten) oder /denken (strukturierte Analyse nach einem festen Argumentations-Schema).
Hooks sind die zweite Schicht. Ein Hook ist ein automatischer Wächter, ungefähr wie ein Rauchmelder: Er hängt unscheinbar an der Decke und schlägt von selbst an, sobald etwas Bestimmtes passiert, bevor oder nachdem die KI etwas tut. Zwei echte Beispiele aus meinem System: „Wenn die KI gerade eine Datei speichern will, prüfe vorher, ob die Festplatte voll ist." Oder: „Wenn der Chat sich dem Ende neigt, dokumentiere offene Punkte automatisch." Das klingt nach Technik-Kleinkram. Aber meiner eigenen Disziplin bei solchen Routine-Prüfungen vertraue ich ungefähr so weit wie einem vollen Posteingang am Freitag. Hooks sind die Disziplin, die der Mensch nicht hat.
Subagenten sind die dritte Schicht. Ein Subagent ist ein hinzugezogener Spezialist mit eigenem, abgegrenztem Aktenordner, der genau eine Aufgabe übernimmt, ungefähr wie ein externer Gutachter, der nur seinen Auftrag kennt und nicht das ganze Unternehmen. Mein Code-Review-Subagent zum Beispiel kennt nur die Code-Review-Regeln, nicht meine Vertriebs-Datenbank. Wenn er fertig ist, gibt er eine Zusammenfassung zurück, nicht das ganze Protokoll. Das hält die Haupt-KI fokussiert und ist die einzige Art, wie Systeme aus mehreren KI-Agenten realistisch beherrschbar bleiben. Ich habe aktuell eine Handvoll spezialisierte Subagenten im Einsatz, unter anderem für Datenanalyse, Recherche-Prüfung und die Beurteilung der Qualität meiner eigenen Skills.

Take-away: Skills, Hooks und Subagenten sind keine drei Tools, sondern drei Hebel. Erst zusammen entsteht ein wiederholbarer Prozess, einzeln bleibt es eine schlauere Suchmaschine.
Wo greife ich noch ein und wo nicht mehr?
Kurzantwort: Die KI macht heute Recherche, Strukturierung, Routine-Schreiben, Bilder und Upload. Ich entscheide über Stimme, Positionierung und Veröffentlichung. Die Übergaben sind dokumentiert und prüfbar, nicht implizit.
Ohne Architektur kippt das Vertrauen in eine der zwei falschen Richtungen: entweder „KI macht das schon", oder „KI darf gar nichts". Beides ist ungesund. Mein Modell heute teilt die Verantwortung sauber auf:
Phase | Wer arbeitet | Wer entscheidet |
Idee + Auftrag | Marcus + KI (Rückfragen) | Marcus |
Recherche (intern + extern) | KI | KI (mit Belegen) |
Gliederung + Suchmaschinen-Vorgaben | KI | Marcus (Stichprobe) |
Erstentwurf | KI | Marcus (Stimme + Logik) |
Faktencheck | KI + Codex (Zweitmeinung) | Marcus (Stichproben) |
Bilder + Infografiken | KI (Konzept + Generierung) | Marcus (Brand-Check) |
Veröffentlichung im CMS der Website | KI (Pipeline) | Marcus (Veröffentlichen-Button) |
Refresh-Loop nach Publish | KI (Trigger-Erkennung) | Marcus (Edit oder nicht) |
Das Wichtige steht in der letzten Zeile. Mein System schlägt mir wöchentlich vor, welche Beiträge eine Aktualisierung brauchen, weil neue Studien reinkamen, sich Microsoft-Features geändert haben oder die Performance einbricht. Die Entscheidung „aktualisieren oder lassen" treffe ich. Auto-Veröffentlichung gibt es bei mir bewusst nicht. Eine bekannte Vorfall-Klasse beim Multi-Agent-System ist genau das: KI veröffentlicht ungeprüft.
Take-away: Vertrauen ja, blindes Vertrauen nein. Die eigentliche Frage ist, wo der Mensch der letzte Filter bleibt. Diese Entscheidung gehört an den Anfang, vor den ersten Skill.
Welche Rolle spielt die Architektur bei Claude Code und Codex im Mittelstand?
Kurzantwort: Den Blog-Workflow hätte ich an einem Wochenende programmieren können. Aber er funktioniert nur, weil über zwei Dutzend Skills aufeinander abgestimmt sind, ein gepflegtes Wissens-Wiki dahintersteht, eine zentrale Datenbank alles konsistent zusammenhält und Dutzende nächtliche Automatisierungen die Wissensbasis aktuell halten. Das war zwei Monate Architekturarbeit, mit täglichem Hand anlegen. Für ein Unternehmen zählt davon vor allem die Reihenfolge des Aufbaus, weniger mein konkretes Werkzeug. Die genauen, live aus der Datenbank gezogenen Zahlen halte ich in einem eigenen technischen Steckbrief aktuell.
Die Harvard Data Science Review führt in ihrer Winter-2026-Ausgabe den Aufsatz „The Agent-Centric Enterprise: Why 2-10x Productivity Gains Demand Radical Workflow Redesign". Die Pointe der Autorinnen: Produktivität in der 2- bis 10-fachen Größenordnung entsteht nicht durch Tool-Kauf, sondern durch Workflows, die für Agenten-Ausführung neu entworfen wurden, mit Menschen in den Rollen Supervision, Ausnahmebehandlung und Verbesserung. Übersetzt: KI in alte Workflows zu kippen, bringt etwas, aber selten den Sprung.
Bei mir sieht „neu entworfen" so aus:
Eine Wahrheitsquelle. Eine zentrale Datenbank, sechs ehemals isolierte Datenstores zusammengeführt. Jede App, jeder Skill, jeder Subagent liest aus dem gleichen Schema.
Wissens-Wiki als zweites Gedächtnis. Tausende verlinkte Markdown-Dokumente, die die KI bei jeder Recherche zuerst konsultiert, bevor sie ins Web geht. Was einmal recherchiert wurde, muss nicht zweimal recherchiert werden.
Skills statt Improvisation. Über zwei Dutzend wiederverwendbare Arbeitsabläufe für die wiederkehrenden Aufgaben (Blog, Lead-Recherche, Posteingang, Analyse, Sales-Calls).
Hooks statt Disziplin. Wenn ich eine Datei bearbeiten will, prüft ein Hook automatisch, ob ich gerade gegen meine eigenen Regeln verstoße (zum Beispiel Klarnamen in einem öffentlichen Dokument).
Subagenten statt Kontext-Überlauf. Jede Spezialaufgabe (Datenanalyse, Skill-Audit, Recherche-Verifikation) hat einen eigenen Subagenten mit eigenem Kontext.
Dutzende nächtliche Automatisierungen (in der Fachsprache Cron-Jobs, im Grunde eine Zeitschaltuhr für wiederkehrende Aufgaben), die nachts Marktnachrichten, Microsoft-Updates und neue Fachartikel aus der KI-Forschung durchsehen. Was relevant ist, liegt morgens sortiert in meinem Posteingang, wie von einer Nachtschicht vorbereitet.
Klingt nach Solo-Berater-Bastelei. Ist es auch. Aber die Mechanik ist dieselbe wie in einem Unternehmen. Ein Multi-Agent-System Mittelstand muss nicht über hundert Tabellen haben. Es braucht aber dieselbe Reihenfolge: Datenbasis, Zuständigkeiten, wiederholbare Skills, Prüfpunkte, dann erst Automatisierung. Gartner prognostiziert, dass bis Ende 2026 rund 40 % der Enterprise Applications task-spezifische KI-Agenten integriert haben werden. 2025 waren es noch weniger als 5 %. Die Richtung steht. Worüber Unternehmen wirklich entscheiden, ist die Architektur dahinter.
Take-away: Tools sind eine Stunde Installation. Architektur ist Wochen Arbeit. Wer diese Reihenfolge umdreht, bezahlt Lizenzen, die niemand richtig nutzt, und korrigiert die Reihenfolge dann doch, nur teurer.
Was das für Ihr Unternehmen heißt
Kurzantwort: Die richtige Frage ist nicht „Welches KI-Tool kaufen wir?", sondern „Haben wir eine Architektur, in die das Tool gehört?". Wer diese Frage überspringt, finanziert die nächste Lizenzwelle, ohne dass sich daraus messbare Veränderung ergibt.
Das wird heute oft falsch gerahmt. Die Sales-Pitches lauten „wir machen Sie Copilot-ready", „wir bringen Ihnen GPT bei". Die echte Frage ist davor: „Wo gehen heute Stunden verloren? Wo entstehen heute Fehler, die niemand sieht? Wo entscheiden Sie auf Basis von Daten, die niemand mehr versteht?"
Konkret und ehrlich, ohne Solo-Berater-Romantik:
Bauen Sie nicht meine Architektur nach. Der Einwand ist berechtigt: ein selbstgebautes Schema mit über hundert Tabellen und über hundert Automatisierungen ist Solo-Hobby, kein Unternehmens-Setup. Übertragbar ist nicht mein Tooling, sondern die Reihenfolge: Datenzugriff klären, Prozess beschreiben, Skill oder Agent erst dann einsetzen. Ein KI-Agenten-System im Mittelstand ist meistens viel kleiner: Microsoft 365 plus Copilot, sauber aufgesetzt, plus zwei bis drei dedizierte Agenten für klare Anwendungsfälle.
Aber denken Sie wie ein Architekt. Bevor Sie eine Copilot-Lizenz pro Mitarbeitenden bezahlen, prüfen Sie die Berechtigungen, die Datenqualität, die SharePoint-Struktur. Sonst halluziniert Ihr Copilot fröhlich auf dem Datenmüll der letzten zehn Jahre (siehe auch meinen Beitrag zu KI-Strategie im Mittelstand).
Investieren Sie in Skills, nicht in Schulungen. Eine Schulung verpufft nach zwei Wochen. Ein dokumentierter Skill für „so machen wir unsere Angebote", „so reviewen wir Verträge", „so läuft unsere Lead-Qualifizierung" bleibt. Skills sind das organisationale Gegenstück zu meinen eigenen Skill-Dateien.
Behalten Sie den Publish-Button. Bei jedem KI-Output, der nach außen geht (E-Mails an Kunden, Angebote, Veröffentlichungen), prüft ein Mensch. Solange Sycophantie und Halluzinationen messbar sind, ist diese Regel nicht verhandelbar.
Drei sinnvolle Starts, je nach Reifegrad:
M365-Governance prüfen, bevor Copilot skaliert. Wenn Ihre SharePoint-Berechtigungen seit drei Jahren niemand mehr angesehen hat, finden Sie mit hoher Wahrscheinlichkeit Teams, deren Inhalt jedem im Unternehmen offensteht: Gehaltslisten, Strategiepapiere und Kundenkommunikation, die Copilot dann gerne in eine Antwort an einen Praktikanten kippt. Der ehrlichste erste Schritt ist nicht eine Lizenzwelle, sondern ein Berechtigungs-Audit.
Einen klaren Content- oder Wissensprozess automatisieren. Wie hier am Blog. Nicht alles auf einmal, sondern einen Prozess, den Sie auch ohne KI sauber beschreiben können.
Einen Skill für einen wiederkehrenden Fachprozess dokumentieren. Zum Beispiel „so qualifizieren wir Leads", „so reviewen wir Verträge". Erst schreiben, dann automatisieren.
Und der ehrliche Gegenfall: Wenn bei Ihnen niemand wiederkehrende Wissensarbeit macht, Ihre Daten ohnehin sauber in einem System liegen und keine Stunden in Suchen, Dubletten oder manuellem Zusammenkopieren verschwinden, brauchen Sie so ein Setup nicht. Ein Agentensystem lohnt sich dort, wo sich Arbeit wiederholt und Wissen heute im Chatverlauf oder in einzelnen Köpfen verschwindet. Nicht als Selbstzweck.
Take-away: Architektur ist nicht Tool. Architektur ist Voraussetzung. Wer mit der Tool-Frage anfängt, kann das Setup hinterher noch lange korrigieren, meistens teurer, als es vorne richtig zu denken.
Wie hilft ein Codex Cross-Review gegen blinde KI-Automatisierung?
Kurzantwort: Ein Codex Cross-Review zwingt den Entwurf durch eine zweite Modellfamilie. Das ersetzt keinen Menschen, senkt aber das Risiko, dass eine KI nur ihren eigenen Text verteidigt.
Der Einwand, den ich von Geschäftsführern am häufigsten höre: „Was, wenn die KI Unsinn baut und ich es zu spät merke?" Berechtigt. Genau deshalb steht am Anfang ein Prüfpfad statt eines Vertrauensvorschusses: eine zweite, fremde KI liest gegen, jede Zahl läuft gegen ihre Quelle, und am Ende drückt ein Mensch den Veröffentlichen-Knopf. Das schließt Fehler nicht aus, aber es erhöht die Chance deutlich, dass sie auffallen, bevor sie nach außen gehen.
Mein System ist ein Solo-Setup, keine Enterprise-Umgebung. Es hat keine Mehrbenutzer-Auditierung, keine regulierungstaugliche Datenhaltung, keine getrennten Mandanten. Das ist Absicht: Es ist mein Lernfeld, nicht mein Produkt. Mehr dazu, und ehrlich beziffert, in Teil 2 zu den belegbaren Schwächen.
Drei Risiken, die ich aktiv überwache:
Sycophantie (gefälliges Zustimmen). Sprachmodelle stimmen Nutzern systematisch zu, auch wenn die Nutzer falsch liegen. Fanous et al. (2025) zeigen im SycEval-Benchmark (das ist eine standardisierte Test-Sammlung): Modelle ändern ihre Antwort unter Nutzer-Widerspruch häufig. Berichte zum Datensatz nennen grob 60 % Antwortwechsel. Mein Gegenmittel: ein Pflicht-Schritt vor jeder Analyse, der die Gegenposition durchspielt, plus das Codex-Cross-Review, das genau diesen Bestätigungs-Reflex von außen prüft.
Halluzinationen, insbesondere bei Quellen. Halluzination heißt: Die KI erfindet glaubwürdig klingende Zitate oder Studien, die es so gar nicht gibt. Mehrere Studien zeigen einen nicht trivialen Anteil solcher erfundenen Zitate. Mein Gegenmittel: jede Studien-Quelle wird gegen meine eigene Evidenz-Datenbank geprüft, jede Zahl gegen die Primärquelle.
Cognitive Debt (Denk-Schulden). Wer die KI lange genug einen Großteil der Denkarbeit machen lässt, verliert über die Zeit eigene Urteilskraft, ähnlich wie ein Muskel, der nicht mehr trainiert wird. Studien (Fan et al. 2025, Akgun & Toker 2025, siehe Teil 2) deuten darauf hin. Mein Gegenmittel ist unromantisch: Stichproben-Pflicht, eigene Recherche zu mindestens einem Schlüsselargument pro großem Beitrag, und alle paar Wochen die ehrliche Frage „verstehe ich noch, was mein System mir vorschlägt?".
Es gibt keine perfekte Antwort darauf. Aber es gibt eine praktikable: Quellenpflicht, Cross-Review, Stichproben und ein menschlicher Publish-Button. Wer alle Risiken ausschließen will, schließt den Nutzen aus. Risiken zu ignorieren, schließt den Nutzen ebenfalls aus, nur später und teurer.
Wie geht es weiter?
Ein letzter ehrlicher Punkt: Bevor dieser Beitrag online ging, und auch vor jeder Aktualisierung, läuft er durch zwei Prüfungen. Erstens das Codex-Cross-Review: Eine zweite, unabhängige KI (in meinem Fall OpenAI Codex mit GPT-5.5) prüft Fakten, Sprache, Konsistenz und schlägt Korrekturen vor. Zweitens das Panel-Review: Hier lasse ich vier verschiedene KI-Rollen den Text aus unterschiedlichen Perspektiven angreifen, nämlich eine Geschäftsführerin, einen IT-Leiter, einen Berater-Kollegen und einen Moderator (das nennt sich „Steel-Man-Verfahren"). Was diese Runde findet und mir entgangen war, arbeite ich ein. Auch das ist Teil meines Blog-Skills, keine Zugabe.
Für diese Fassung hieß das konkret: Der AI-Act-Hinweis wurde präzisiert, weil die Pflicht nicht pauschal für jeden KI-unterstützten Blogtext gilt. Der manuell gesetzte Link zur Terminbuchung wurde entfernt, weil die Blog-Pipeline den Button sauber aus den Metadaten rendert. Und die letzte Qualitätsentscheidung blieb bei mir, nicht beim Agentensystem.
Wenn Sie prüfen wollen, ob ein automatisierter Prozess wie dieser bei Ihnen sinnvoll ist, starten wir am besten mit drei Fragen:
Wer darf welche Inhalte sehen? Und wer im Unternehmen weiß das wirklich verlässlich? Diese eine Frage entscheidet zu 80 %, ob Ihre KI-Einführung zum Erfolg oder zum Compliance-Ereignis wird.
Wo liegen Ihre Inhalte und Daten heute? SharePoint, OneDrive, Fileserver, Excel-Inseln, Teams-Chats: verteilt oder konsolidiert?
Welcher Prozess wiederholt sich bei Ihnen jede Woche und wird trotzdem jedes Mal neu improvisiert? Genau dort liegt der erste sinnvolle Agent.
Nach diesen drei Fragen ist meistens klar, ob Copilot allein schon reicht, ob ein dedizierter Agent für einen klaren Anwendungsfall sinnvoll ist, oder ob die ehrlichere Antwort „erst Berechtigungen und Datenqualität, dann KI" heißt. Beides ist ein guter Stand. Ich höre mir Ihren Fall gerne in 30 Minuten an.
Über den Autor: Marcus Machon berät mittelständische Unternehmen bei Microsoft 365 Governance, SharePoint-/Teams-Struktur, Power-Platform-Automatisierung und Copilot-/KI-Readiness.
Quellen
Kruhse-Lehtonen, U. & Hofmann, D. (2026): The Agent-Centric Enterprise. Why 2-10x Productivity Gains Demand Radical Workflow Redesign. Harvard Data Science Review 8.1. https://hdsr.mitpress.mit.edu/pub/0mrfxamu/release/3
Anthropic Engineering (2026): Equipping agents for the real world with Agent Skills. https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
Fanous, A. et al. (2025): SycEval, Evaluating Sycophancy in Large Language Models. arXiv:2502.08177. https://arxiv.org/abs/2502.08177
Gartner (2025): Forecast, 40 % of enterprise applications will embed task-specific AI agents by 2026. https://www.gartner.com/en/newsroom/press-releases/2025-08-26-gartner-predicts-40-percent-of-enterprise-apps-will-feature-task-specific-ai-agents-by-2026-up-from-less-than-5-percent-in-2025
Europäische Kommission (2026): AI Act Service Desk, Artikel 50 Transparenzpflichten. https://ai-act-service-desk.ec.europa.eu/de/ai-act/article-50
Chakrabarty, T., Laban, P. & Wu, C.-S. (2025): Can AI Writing Be Salvaged? Typische Eigenheiten von KI-Texten wie Floskeln und überflüssige Erklärungen. arXiv:2409.14509. https://arxiv.org/abs/2409.14509
Russell, J., Rajendhran, R., Pham, C. M., Iyyer, M. & Wieting, J. (2026): StoryScope. KI-Texte sind an Diskurs- und Erzählmustern erkennbar (93,2 % macro-F1 allein über Narrativ-Merkmale); oberflächliches Editieren senkt die Erkennung kaum. arXiv:2604.03136. https://arxiv.org/abs/2604.03136


