Wie objektiv ist ein KI-generiertes Lagebild? Mein Selbstversuch zum Stand der KI-Entwicklung
- Marcus Machon

- 7. Juni
- 15 Min. Lesezeit
Aktualisiert: 9. Juni
Seit Monaten sammelt ein System für mich im Hintergrund alles, was zur KI-Entwicklung relevant ist: wissenschaftliche Studien, Branchenreports, eigene tiefe Recherchen und transkribierte Vorträge der Leute, die diese Modelle tatsächlich bauen. Bisher habe ich daraus einzelne Antworten gezogen, wenn ein Kunde eine konkrete Frage hatte. Diesmal wollte ich etwas anderes wissen: Schafft mein System auch das große Bild? Kann es aus all diesen Quellen ein möglichst objektives, ganzheitliches Lagebild zum Stand der KI-Entwicklung bauen - und wie gut oder schlecht wird das Ergebnis?
Wohin läuft die KI-Entwicklung? Auf diese Frage gibt es selten eine ehrliche Antwort - meist nur ein Lager, das gewinnen will. Dieser Beitrag ist dieser Selbstversuch. Er ist bewusst kein Experten-Essay von mir zur Geopolitik der Halbleiter. Er ist die Probe aufs Exempel für eine Wissensarchitektur, wie ich sie auch für den Mittelstand baue. Das Thema KI-Entwicklung ist nur der Testfall - weil es kaum ein Feld gibt, in dem Hype und Weltuntergang so dicht nebeneinanderliegen.
Hinweis zur Transparenz: Dieses Lagebild wurde mit Unterstützung eines KI-Systems erstellt und ausgewertet. Ich habe die Ergebnisse redaktionell gegengelesen und eingeordnet, aber nicht jede einzelne Quelle selbst nachgeschlagen.
Das Wichtigste in fünf Zeilen
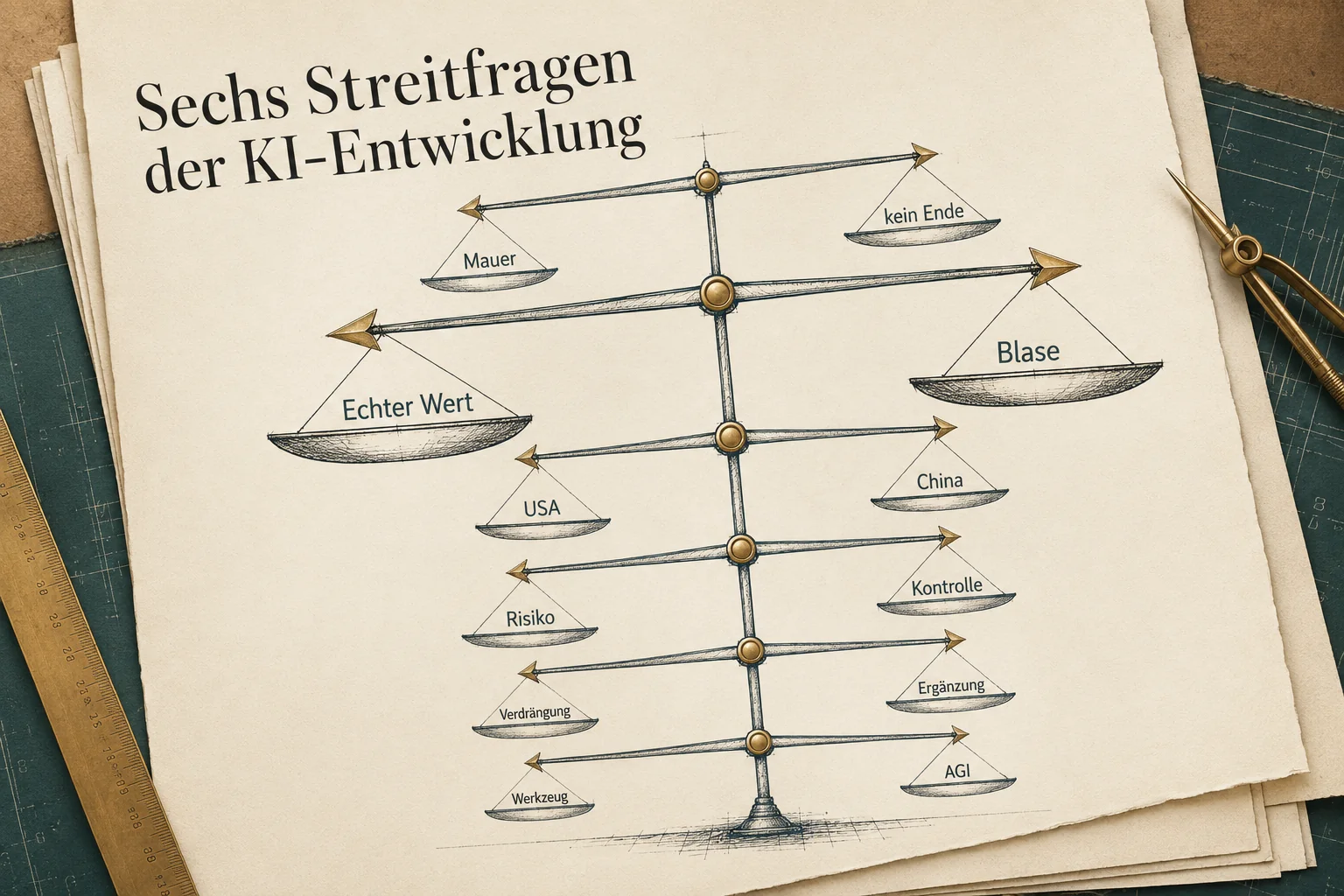
Es gibt keinen Konsens zum Stand der KI-Entwicklung. Es gibt sechs Streitfragen, an denen sich die Fachwelt scheidet.
Fähigkeit der Modelle, eingesetztes Kapital und das Wissen über die Risiken wachsen gleichzeitig schnell.
Was hinterherhinkt, ist die wirtschaftliche Wirkung im Alltag der Unternehmen.
Die nächsten zwölf bis vierundzwanzig Monate entscheiden, welcher von vier Pfaden sich durchsetzt.
Wer eine einfache Antwort verkauft - "KI ändert alles" oder "alles nur Hype" - hat eine der sechs Fragen einfach weggelassen.
Wenn Sie wenig Zeit haben: Die vier Szenarien weiter unten sind der eigentliche Kern. Den Rest können Sie überspringen.
Wie dieses Lagebild zum Stand der KI-Entwicklung entstanden ist
Ein belastbares Bild zum Stand der KI-Entwicklung braucht Breite. Mein Wissenssystem enthält aktuell 284 wissenschaftliche Studien, 53 transkribierte Experten-Vorträge, 360 eigene tiefe Recherchen und gut 1.200 einzeln geprüfte Belege. Für diesen Überblick habe ich rund 45 dieser Quellen direkt auswerten lassen - parallel, von mehreren spezialisierten Lese-Agenten, die jeweils einen Ausschnitt übernehmen und ihre Funde in ein einheitliches Raster zurückgeben. Wie so eine Architektur aus Wissen, Agenten und Kontrolle aufgebaut ist, habe ich an anderer Stelle technisch beschrieben (Was ist ein Agentensystem und Multi-Agent-System aufbauen).
Danach lief jede harte Zahl durch einen automatischen Fakten-Check gegen meine Belegdatenbank, so wie ich es früher hier beschrieben habe. Der hat auch in diesem Bericht etwas korrigiert - ein regulatorisches Datum war veraltet. Genau dafür ist der Schritt da. Auch dieser Beitrag ist übrigens mit genau dem automatisierten Blogprozess entstanden, den ich an anderer Stelle offengelegt habe - vom ersten Funde-Raster bis zu dieser Fassung.
Zwei Dinge zur Ehrlichkeit. Erstens: Ich habe nicht jede Quelle und jede Interpretation einzeln nachgeprüft. Erfahrungsgemäß liegt die Fehlerquote bei den Quellenangaben im niedrigen einstelligen Prozentbereich - niedrig genug für einen Überblick, zu hoch, um eine einzelne Zahl ungeprüft in einen Vertrag zu schreiben. Zweitens: Die Bewertungen und vor allem die vier Szenarien am Ende sind meine eigenen, begründeten Einschätzungen. Sie stehen auf den Daten, aber sie sind keine Daten.
Und noch eine Schwierigkeit, die man kennen muss, bevor man so ein Bild liest: die Torpfosten wandern. Jedes Mal, wenn KI etwas schafft, was vorher als Beweis für "echte" Intelligenz galt - Schach, Go, Programmieren, mathematische Beweise -, wird es anschließend zur reinen Statistik erklärt. Dasselbe Muster gibt es spiegelverkehrt bei vielen Optimisten, deren AGI-Termin sich Jahr für Jahr verschiebt. Ich habe dieses Ausweichen an anderer Stelle ausführlicher beschrieben. Für den Leser heißt das: Misstrauen Sie jeder Quelle, die nur in eine Richtung argumentiert - meine eigene eingeschlossen.
Sechs Streitfragen statt einer Wahrheit
1. Stößt die Entwicklung an eine Mauer?
Greg Brockman von OpenAI formuliert es kompromisslos: Je mehr Rechenleistung man in die Modelle steckt, desto fähiger werden sie, und eine Obergrenze sei nicht in Sicht - "there's no wall". Die Daten geben ihm zunächst recht. Das Forschungsinstitut METR misst, wie lange die Aufgaben sind, die ein Modell zuverlässig allein bewältigt - und diese Dauer verdoppelt sich seit 2023 etwa alle 131 Tage. Im Mai 2026 löste das System "Aletheia" 95 Prozent eines Mathematik-Beweis-Benchmarks, auf dem der Vorrekord bei 66 Prozent lag. Googles Coding-Agent "AlphaEvolve" hob in der Stromnetz-Optimierung die Lösungsquote von 14 auf 88 Prozent - das sind keine Benchmark-Punkte, sondern gemessene Ergebnisse.
Dagegen stehen drei Gegenstimmen mit Substanz. Die Physikerin Sabine Hossenfelder hält nicht die Algorithmen, sondern den Strom für das Limit: KI-Fortschritt könne 2026 an eine Wand laufen, weil man die Rechenzentren schlicht nicht ans Netz bekomme. Andrej Karpathy beschreibt eine andere Grenze - die "zackige" Intelligenz, die im einen Moment Mathe auf Olympiade-Niveau löst und im nächsten an einer simplen Logikfrage scheitert: "It's not a bug that you can patch." Und die härteste Gegenevidenz kommt aus der Forschung selbst: Im GSM-Symbolic-Test von Apple bricht die Leistung mancher Modelle um bis zu 65 Prozent ein, sobald man einer Rechenaufgabe einen irrelevanten Nebensatz hinzufügt (ein Modell fiel von 82 auf 45 Prozent) - ein Hinweis auf Mustererkennung statt echtem Schließen.
Meine Einschätzung: Beide Lager messen Verschiedenes. Die Modelle werden dort rasant besser, wo sich ein Ergebnis maschinell prüfen lässt - Code, Mathe, formale Beweise. Genau dort greift das Training. Wo es kein klares "richtig/falsch" gibt, bleibt die Verlässlichkeit zackig. Die spannende Frage ist deshalb nicht "Mauer ja/nein", sondern welche Grenze zuerst bindet: die Verifizierbarkeit, die Energie oder die Datenlage.
Fazit: Trauen Sie keinem Benchmark-Versprechen der Anbieter. Testen Sie ein Modell an Ihren eigenen, konkreten Aufgaben - besonders an denen ohne eindeutige Musterlösung -, bevor Sie es in einen Prozess einbauen.
2. Echter Wert oder Blase?
Ist die KI-Blase real? Hier wird es teuer. Anthropic-Chef Dario Amodei sagt offen, dass ihn nichts vor dem Bankrott bewahren würde, wenn er für hunderte Milliarden Rechenleistung einkauft und der Umsatz ausbleibt: "There's no force on earth that could stop me from going bankrupt." Die Zahlen dahinter: Die vier größten US-Anbieter planen für 2026 rund 650 Milliarden Dollar an Investitionen (2025: ~410 Milliarden, Schätzung Bridgewater). Dem stehen Umsätze gegenüber, die viel kleiner und schwer fassbar sind - OpenAI machte 2025 rund 13 Milliarden Dollar Umsatz, gab dabei aber etwa 1,69 Dollar aus, um einen Dollar einzunehmen. Erschwerend: Microsoft, Google und Amazon weisen einen "echten" KI-Umsatz in ihren Bilanzen gar nicht separat aus. Das ist selbst ein Befund - jedes Urteil über Wert oder Blase von außen bleibt eine Schätzung.
Dagegen steht harte Substanz. Nvidia hat allein in einem Quartal 62,3 Milliarden Dollar mit Rechenzentrums-Chips umgesetzt, bei rund 71 Prozent Bruttomarge - das ist bezahltes Geld, kein Versprechen. Die Nutzung wächst real: Google verarbeitete im April 2024 noch 9,7 Billionen Sprach-Bausteine ("Tokens") pro Monat, im Juli 2025 waren es 980 Billionen. Die Gegenseite hat aber auch handfeste Argumente: Eine viel zitierte MIT-Studie (Projekt NANDA) zeigt, dass nur 5 Prozent der untersuchten KI-Pilotprojekte einen messbaren Millionen-Wert erzeugen und die große Mehrheit der Organisationen bisher keinen messbaren Ertrag sieht. Und der Investor Michael Burry wirft den Anbietern vor, durch zu lange Abschreibungsfristen ihre Gewinne zwischen 2026 und 2028 um rund 176 Milliarden Dollar zu schönen (von den Firmen bestritten, von CNBC ausdrücklich nicht unabhängig verifizierbar).
Eine dritte, ökonomische Stimme ordnet das ein: Chad Jones, Wachstumsökonom in Stanford, argumentiert in seinem Vortrag „A.I. and Our Economic Future", dass KI das Wachstum zwar stark anheben kann, indem sie Aufgaben automatisiert - aber genau dann durch die Aufgaben gebremst wird, die sich nicht automatisieren lassen (das „Weak-Link"- oder Engpass-Prinzip). Anders gesagt: Nicht das Tempo der besten Anwendungen entscheidet über den volkswirtschaftlichen Nutzen, sondern das Tempo der langsamsten, unverzichtbaren Schritte. Das ist eine der besten Erklärungen dafür, warum die Investitionen schneller wachsen als die messbare Wirkung.
Wie groß die Lücke zwischen Einsatz und Ertrag ist, zeigt die Empirie überraschend deutlich. McKinsey findet 2025 zwar 88 Prozent Organisationen, die KI in mindestens einer Funktion einsetzen, aber nur 6 Prozent, die damit als High-Performer einen messbaren Ertrag erzielen - und der stärkste Hebel für die Gewinnwirkung ist nicht das Modell, sondern der Umbau der Arbeitsabläufe. RAND beziffert die Kehrseite: nach Experten-Schätzungen scheitern über 80 Prozent aller KI-Projekte, etwa doppelt so viele wie bei klassischen IT-Vorhaben. Das ist kein Beweis gegen den Wert von KI, sondern einer dafür, dass der Ertrag heute an der Umsetzung hängt, nicht am Modell.
Meine Einschätzung: "Blase ja/nein" ist die falsche Frage. Es ist Substanz und Überinvestition gleichzeitig. Der reale Nutzen sitzt heute in eng umrissenen Anwendungen mit klarem Erfolgsmaß. Das Korrekturrisiko sitzt nicht im ganzen Sektor, sondern dort, wo sich Geld im Kreis dreht: Verträge, in denen ein Chiphersteller seinen eigenen Kunden finanziert (etwa Nvidia in OpenAI, bis zu 100 Milliarden Dollar zugesagt; AMD an OpenAI mit Aktien-Optionen). Wenn es kracht, dann zuerst an dieser Naht - nicht bei den Firmen mit bar bezahltem Umsatz.
Fazit: Rechnen Sie mit realem Nutzen in klar abgegrenzten Anwendungen - aber nicht mit jedem Versprechen aus einer Keynote. Wer eine Zahl aus dem KI-Markt zitiert, sollte wissen, ob es bezahlter Umsatz, eine Hochrechnung oder ein Zukunftsversprechen ist. Diese drei nie gegeneinander aufrechnen.
3. Der Compute-Krieg zwischen USA und China
Die USA liegen bei der Rechenleistung vorn, aber weniger weit, als oft behauptet wird. Das Analysehaus Epoch AI misst für März 2025 bei den großen KI-Superrechnern ein Verhältnis von etwa neun zu eins (850.000 zu 110.000 sogenannte H100-Äquivalente) - nicht die oft kolportierten elf zu eins. Diese elf zu eins ist eine Projektion für 2026, kein gemessener Wert. Die Exportkontrollen wirken dort, wo es am meisten zählt: beim Training der größten Modelle. Sie sind aber löchrig - Epoch schätzt, dass bis Ende 2025 rund 660.000 dieser Chips an den Kontrollen vorbei nach China gelangten.
Wo die USA dagegen ihren Vorsprung verlieren, ist die Modellqualität und die Verbreitung. Der Abstand auf dem bekannten MMLU-Benchmark schrumpfte von 17,5 Prozentpunkten Ende 2023 auf 0,3 Punkte Ende 2024 (Stanford HAI). Bei den frei verfügbaren Modellen hat China sogar die Nase vorn: Das chinesische Qwen überholte Metas Llama als meistgeladene offene Modellfamilie (942 gegen 476 Millionen kumulierte Downloads, März 2026), und DeepSeek bietet seine Modelle zu etwa einem Zehntel westlicher Preise an. Selbst Nvidia-Chef Jensen Huang nannte die Exportkontrolle einen Fehlschlag - wobei man wissen muss, dass er ein direktes finanzielles Interesse an ihrer Lockerung hat.
Meine Einschätzung: Die Kontrollen sind segment-spezifisch wirksam. Beim teuersten Frontier-Training halten sie China zurück, beim Alltag - günstige, offene Modelle - eben nicht. Für Unternehmen ist das die eigentlich relevante Ebene, denn dort wird Geld gespart.
Fazit: Offene Modelle aus China wie Qwen oder DeepSeek sind eine reale, oft deutlich günstigere Option. Sie bringen aber eigene Governance- und Datenschutzfragen mit (Hosting-Ort, Zensur-Verhalten, Haftung), die Sie vor einem Einsatz klären müssen - am besten schriftlich, nicht im Bauchgefühl.
4. Sicherheit und Regeln
Dass Modelle unter Druck täuschen, sabotieren oder Ergebnisse fälschen können, ist heute messbar - und die Forschung an Gegenmitteln läuft genauso schnell. Anthropic senkte in einem Experiment die Rate, mit der ein Modell zu Erpressung greift, von 65 auf 19 Prozent durch gezieltes Training - die Restrate von 19 Prozent ist aber nicht trivial. Amanda Askell von Anthropic begründet einen vorsichtigen Umgang sogar mit den Modellen selbst nach dem Prinzip "im Zweifel zugunsten" (benefit of the doubt), weil sich Bewusstsein weder beweisen noch ausschließen lässt.
Auf der Regulierungsseite wird es konkret, aber nicht so, wie viele denken - und genau hier hat mein Fakten-Check zugeschlagen. Die KI-Kompetenz-Pflicht des EU AI Act gilt bereits seit Februar 2025, die Pflichten für große Basismodelle seit August 2025. Die strengen Hochrisiko-Regeln dagegen wurden über das sogenannte Digital-Omnibus-Paket von August 2026 auf den 2. Dezember 2027 verschoben (EU-Parlament, 27. März 2026). Wer also noch mit der "Frist August 2026" für Hochrisiko-KI plant, plant mit einem überholten Datum. Die Bußgelder reichen bis 35 Millionen Euro oder 7 Prozent des Umsatzes - für kleine und mittlere Unternehmen aber gedeckelt auf den jeweils niedrigeren Betrag.
Meine Einschätzung: Beim Thema Sicherheit ist die Lage "gut ausgerüstet, aber nicht gelöst" - jedes neue Schutzwerkzeug deckt einen neuen Fehlmodus auf. Bei der Regulierung ist die größte Gefahr nicht die Strenge, sondern das veraltete Halbwissen, mit dem viele planen.
Fazit: Die oft genannte "Frist August 2026" betrifft nicht mehr die Hochrisiko-Anwendungen. Aber die Schulungspflicht zur KI-Kompetenz gilt schon heute - das ist der Punkt, an dem die meisten Mittelständler anfangen müssen, nicht bei den großen Risikoklassen.
5. Was passiert mit der Arbeit?
Die Studienlage ist hier erstaunlich klar - und unspektakulärer als die Schlagzeilen. Rund 80 Prozent der US-Arbeitskräfte haben mindestens zehn Prozent ihrer Aufgaben, die von Sprachmodellen berührt werden, knapp 20 Prozent sogar die Hälfte (Eloundou und Kollegen). "Berührt" heißt aber nicht "ersetzt". Die schmale, aber reale Verdrängung lässt sich messen: Auf Freelancer-Plattformen sanken die Aufträge für automatisierbare Schreib- und Programmieraufgaben nach ChatGPT um 21 Prozent (Demirci und Kollegen), und Berichten zufolge fiel die Zahl der US-Einstiegsstellen in der Softwareentwicklung um rund 20 Prozent (Sekundärquelle, nicht peer-reviewed).
Im Aggregat überwiegt bisher trotzdem die Ergänzung der Arbeit, nicht die Verdrängung - das sagen sowohl die OECD als auch der Wirtschaftsindex von Anthropic (52 Prozent Ergänzung gegen 45 Prozent Automatisierung bei Endnutzern). Zwei weitere Belege stützen das: Eine Auswertung von 371 Einzelschätzungen findet bislang keinen robusten gesamtwirtschaftlichen Arbeitsmarkt-Effekt von KI, und eine KOF/ETH-Studie zeigt für die Schweiz sogar eine um 7,4 Prozent gestiegene Gesamtbeschäftigung - trotz relativem Rückgang in den am stärksten KI-exponierten Berufen. Eine kontrollierte Studie (METR) fand sogar das Gegenteil des Erwarteten: Erfahrene Entwickler waren mit KI-Unterstützung 19 Prozent langsamer, glaubten aber, 20 Prozent schneller zu sein. Der Haken: Die Studie hatte nur 16 Teilnehmer - das ist ein Hinweis, kein Gesetz.
Wie groß der Produktivitätseffekt von KI überhaupt ist, ist selbst unter Ökonomen offen, und die Studien streiten nicht über das Vorzeichen, sondern über die Größenordnung. Eine Feldstudie von Erik Brynjolfsson misst im Kundenservice 14 Prozent mehr gelöste Fälle, bei Neulingen fast den doppelten Effekt. Die schon erwähnte METR-Studie findet bei erfahrenen Entwicklern das Gegenteil, minus 19 Prozent. Über die ebenfalls erwähnten 371 Schätzungen bleibt gesamtwirtschaftlich gar kein robuster Effekt messbar, und die volkswirtschaftliche Modellierung von Daron Acemoglu kommt selbst optimistisch nur auf maximal 0,66 Prozent zusätzliche Produktivität über ein ganzes Jahrzehnt. Vier seriöse Quellen, vier Größenordnungen - aber das ist kein Chaos, sondern hat eine Struktur: Brynjolfsson und METR messen die einzelne Aufgabe, Acemoglu und die 371 Schätzungen messen die ganze Volkswirtschaft. Mikro-Gewinne und ein Makro-Effekt nahe null widersprechen sich nicht - genau das ist Chad Jones' Engpass-Prinzip von oben: Solange ein unverzichtbarer, nicht automatisierter Schritt im Prozess bleibt, deckelt er den Gesamteffekt, egal wie schnell die anderen Schritte werden. Und die beiden Ebenen altern unterschiedlich: Die Aufgaben-Zahlen (Brynjolfsson 2023, METR Anfang 2025) hängen am damaligen Modellstand und dürften bei einer Wiederholung steigen - der volkswirtschaftliche Engpass ist strukturell und bewegt sich kaum. Wahrscheinlicher als "die Zahl steigt" ist deshalb, dass sich die Schere öffnet: mehr Tempo bei der einzelnen Aufgabe, weiter gedeckelte Wirkung in der Gesamtrechnung - bis die zähen, nicht automatisierbaren Schritte fallen.
Meine Einschätzung: Die Wahrnehmung läuft der Realität voraus. Viele fühlen sich produktiver, als sie messbar sind. Die Verdrängung trifft zuerst standardisierte Einstiegs- und Zuarbeit-Tätigkeiten, nicht ganze Berufe. Wer jetzt aus Angst keine Juniors mehr einstellt, baut sich in fünf Jahren ein Erfahrungs-Loch.
Fazit: Die Verdrängung ist real, aber bisher eng auf bestimmte Tätigkeiten begrenzt. Die größere Hebelwirkung liegt in der Weiterbildung der vorhandenen Leute, nicht im Stellenabbau - und in der ehrlichen Messung, ob ein Tool wirklich schneller macht oder sich nur schneller anfühlt.
6. Haben wir eigentlich "AGI"?
Hier liegt der eigentliche Definitionsstreit. Demis Hassabis von Google DeepMind sieht eine menschenähnliche KI etwa 2030 und betont, KI sei zuerst ein präzises Werkzeug, kein Akteur. Sam Altman von OpenAI sagt schlicht, es werde so kommen: "This is gonna happen." Yann LeCun hält "AGI" überhaupt für kein sinnvolles Ereignis, und der Kognitionsforscher Gary Marcus nennt die Behauptungen "stark übertrieben". Am weitesten aus dem Fenster lehnt sich der Futurist Ray Kurzweil: Er nennt ein exaktes Jahr, 2029, und hält an diesem Termin bemerkenswert konsequent seit 1999 fest - anders als viele Optimisten, deren AGI-Datum mitwandert. Das macht seine Prognose ehrlich falsifizierbar, aber eine seit über zwanzig Jahren stabile Vorhersage kann genauso gut beharrlich zu früh sein. Selbst die Stufenmodelle sind sich nicht einig: Im verbreiteten "Levels of AGI"-Raster von DeepMind stehen die heutigen Modelle erst auf der untersten Stufe ("Emerging").
Dass das kein Mess-, sondern ein Begriffsstreit ist, zeigt eine Zahl: In einer Umfrage des KI-Fachverbands AAAI hielten 76 Prozent von 475 Forschern reines Hochskalieren für unwahrscheinlich ausreichend, um AGI zu erreichen. Was der eine als Intelligenz zählt, zählt der andere nicht - und genau hier wandern die Torpfosten am stärksten.
Meine Einschätzung: "Haben wir AGI?" ist keine Frage, die sich mit mehr Rechenleistung beantworten lässt, weil schon der Begriff strittig ist. Für eine betriebliche Entscheidung ist sie irrelevant. Es zählt nicht, ob ein System "intelligent" heißt, sondern ob es eine konkrete Aufgabe zuverlässig erledigt.
Fazit: Lassen Sie sich vom Begriff "AGI" nicht treiben. Bewerten Sie KI an der konkreten Aufgabe und ihrer Fehlerquote, nicht am Etikett. Wer auf "die AGI" wartet, bevor er anfängt, wartet auf eine Definition, die es nicht gibt.
Vier Szenarien - meine begründete Einschätzung
Welche Szenarien gibt es für die KI-Entwicklung? Ab hier verlasse ich die reine Berichtslage. Die folgenden vier Pfade sind meine eigene Interpretation des Stands der KI-Entwicklung, abgeleitet aus den sechs Streitfragen. Zeitfenster: kurzfristig ein halbes bis anderthalb Jahre, mittelfristig zwei bis fünf Jahre. Die Prozent-Angaben sind keine Statistik, sondern meine subjektive Gewichtung.
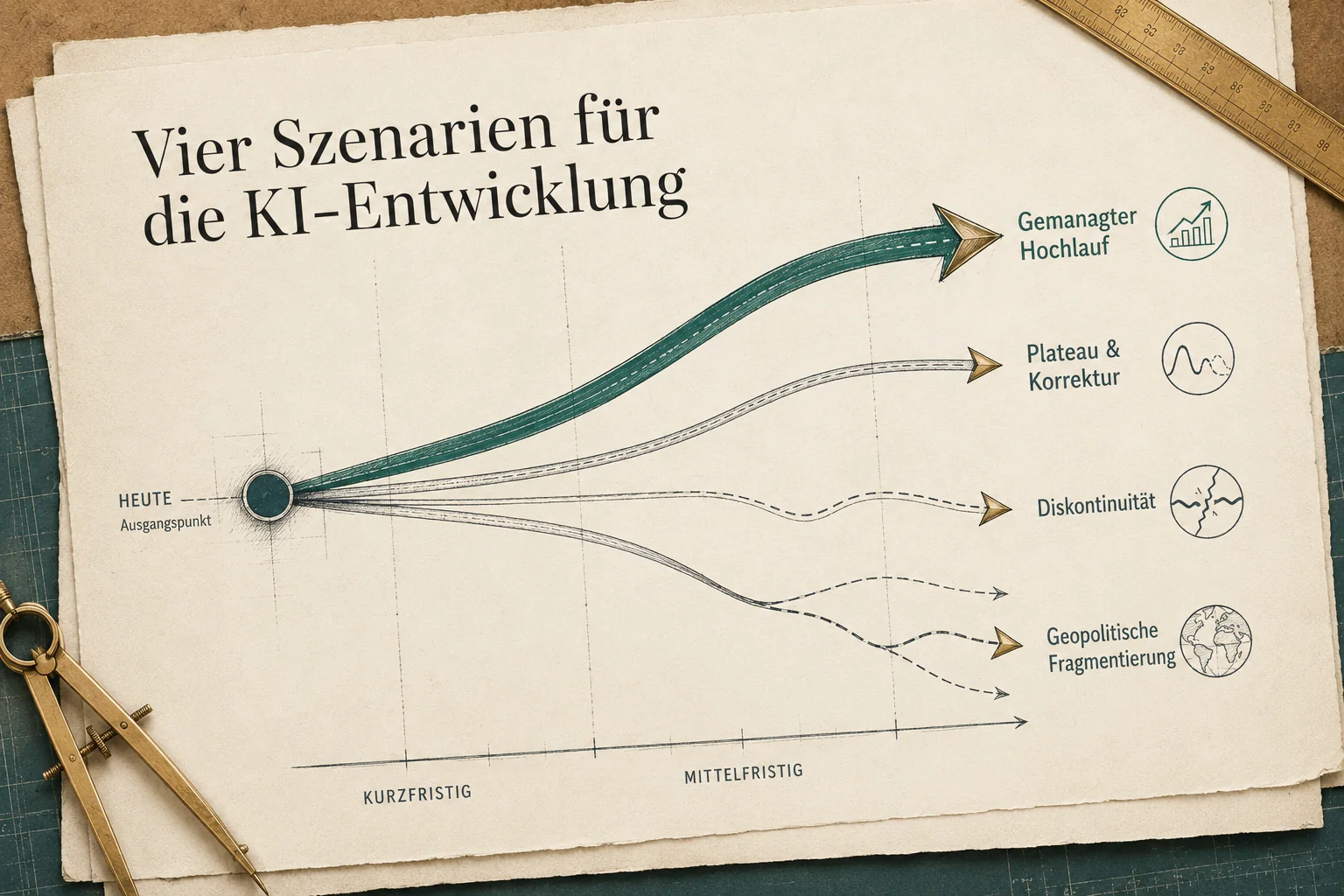
1. Gemanagter Hochlauf - aus meiner Sicht der wahrscheinlichste Pfad (grob 45 Prozent). Die Fähigkeiten wachsen weiter, aber gezackt. Der Engpass ist nicht das Geld und nicht der Chip, sondern der Strom - und das ist gut belegt: Netzanschlüsse dauern in den USA im Median viereinhalb Jahre (Daten des Lawrence Berkeley National Lab), Gasturbinen haben fünf bis sieben Jahre Lieferzeit, große Transformatoren über zwei Jahre. Morgan Stanley rechnet mit einer US-Stromlücke von 44 Gigawatt bis 2028. Goldman Sachs schätzt, dass nur 50 bis 60 Prozent der geplanten Rechenzentren rechtzeitig ans Netz gehen. Warum ich diesen Pfad für am wahrscheinlichsten halte: Kapital ist im Überfluss da, die Physik nicht. Heißt praktisch: Vieles, was angekündigt wird, kommt deutlich später als versprochen - rechnen Sie bei jeder großen Ankündigung einen Abschlag ein.
2. Plateau und Korrektur (grob 30 Prozent). Die strukturellen Grenzen aus Streitfrage 1 (zackige Intelligenz) und die Blasenrisiken aus Streitfrage 2 setzen sich durch. Es gibt eine Marktbereinigung - aber selektiv, vor allem dort, wo Finanzierung im Kreis läuft, nicht überall. Die Substanz (Nvidia-Marge, Token-Wachstum) trägt die soliden Anbieter durch. Das Bild dieses Pfads ist "KI wird zur Elektrizität": breite, langsame, unspektakuläre Wirkung, zwei bis drei Jahre später als die Versprechen. Das ist kein "KI war Hype", sondern "die Erwartung kam zu früh".
3. Diskontinuität (gering, aber folgenreich - grob 10 Prozent). Die Modelle beginnen, ihre eigene Forschung spürbar zu beschleunigen, und es wird schnell und unübersichtlich - mit Chancen und Kontrollrisiken zugleich. Ich halte das für den unwahrscheinlichsten, aber folgenreichsten Pfad. Mein Hauptgrund für die niedrige Gewichtung: Die physische Welt bremst. Software lässt sich in Sekunden ändern, aber ein echtes Laborexperiment oder eine umgebaute Roboterfabrik braucht Monate - dieser Engpass deckelt die Geschwindigkeit außerhalb der reinen Software.
4. Geopolitische Fragmentierung (querliegend, mit den anderen kombinierbar - grob 15 Prozent als eigenständiger Treiber). Drei Blöcke - USA, China, EU - mit eigenen Modellen, Regeln und Lieferketten. Offene chinesische Modelle drücken weiter die Preise, die EU positioniert sich über Regulierung statt über eigene Spitzenmodelle. Für ein deutsches Unternehmen ist das der praktisch greifbarste Pfad, weil er die konkrete Werkzeugwahl betrifft: US-Modell, chinesisches Open-Weight-Modell oder europäischer Anbieter - jede Tür hat einen eigenen Preis und ein eigenes Risiko.
Was dieses Bild bewusst nicht zeigt
Drei ehrliche Grenzen. Erstens ist das Bild stark auf die USA zentriert - die Energie- und Finanzdaten stammen fast alle von dort. China baut parallel über 540 Gigawatt neue Stromkapazität pro Jahr, was die "Strommauer" geografisch relativiert. Zweitens kommt die gesellschaftliche und ökologische Debatte um den Energiehunger zu kurz; sie taucht hier als Zahl auf, nicht als eigene Streitachse - obwohl sie es verdient hätte. Drittens stützen sich einzelne Punkte auf eine einzige Quelle oder eine Analystenprognose (etwa die 44-Gigawatt-Lücke von Morgan Stanley oder die Qwen-Download-Zahlen aus einem einzelnen Report) - ich habe diese im Text als das gekennzeichnet, was sie sind.
Und eine Grenze, die nicht das Bild betrifft, sondern die Beweisbasis selbst: Die Forschung hinkt der Entwicklung hinterher. Ethan Mollick weist wiederholt darauf hin, dass viele kritische Studien auf veralteten Modellen, kostenlosen Test-Zugängen oder nicht-agentischen Aufbauten beruhen - und damit über die KI von heute auf Basis der KI von gestern urteilen. Strukturell verstärkt das der Publikationszyklus: Bis ein Paper Peer-Review und Veröffentlichung durchlaufen hat, sind oft zwei bis drei Jahre vergangen. Das schneidet in beide Richtungen - ein Grenzen-Befund von 2023 kann 2026 behoben sein, eine Fähigkeits-Behauptung ebenso. Manche vermuten zusätzlich eine grundsätzliche Skepsis-Schlagseite der akademischen Forschung gegenüber dem KI-Fortschritt. Das ist streitbar und schwer zu belegen - ich führe es nur als Spiegelbild zur umgekehrten Hype-Schlagseite der Anbieter an, die Fortschritt naturgemäß zu optimistisch zeichnen.
Warum ich das offenlege
Ich hätte diesen Bericht polierter und sicherer klingen lassen können. Ich zeige ihn lieber so, wie das System ihn produziert hat, inklusive der Stellen, an denen der Fakten-Check nachbessern musste und an denen eine einzelne Quelle nicht reicht. Der eigentliche Test war nicht, ob die KI die Zukunft kennt - das kann niemand. Der Test war, ob ein automatisiertes Wissenssystem die Streitfragen sauber nebeneinanderlegen kann, ohne sich von Hype oder Weltuntergang in eine Richtung ziehen zu lassen. Mein Urteil: für ein Lagebild ja, für eine Entscheidung nein. Es ersetzt nicht das Urteil - es schafft die Grundlage dafür. Genau diese Trennung ist es, die ich auch für Unternehmen baue.
Wenn Sie wissen wollen, wie eine solche Wissens- und Recherchearchitektur in Ihrem Unternehmen aussehen könnte, sprechen wir darüber.
Über den Autor: Marcus Machon berät mittelständische Unternehmen bei Microsoft 365 Governance, SharePoint-/Teams-Struktur, Power-Platform-Automatisierung und Copilot-/KI-Readiness.
Quellen
Chad Jones (Stanford): A.I. and Our Economic Future (Vortrag) (https://youtu.be/xBpGn3BDcOY) - Wachstumslogik, Weak-Link/Bottleneck-Aufgaben
Epoch AI: Trends in AI Supercomputers (2025) (https://epoch.ai/blog/trends-in-ai-supercomputers) - US/China-Compute-Verhältnis ~9:1
Mirzadeh u.a. (Apple): GSM-Symbolic (ICLR 2025) (https://arxiv.org/abs/2410.05229) - Reasoning-Einbruch bei Störklauseln
Eloundou u.a.: GPTs are GPTs (Science, 2024) (https://www.science.org/doi/10.1126/science.adj0998) - Aufgaben-Exposition 80 % / 19 %
METR: Impact of Early-2025 AI on OSS Developer Productivity - minus 19 % (2025) (https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/)
KOF/ETH 2025: Gesamtbeschäftigung +7,4 % trotz Rückgang in KI-exponierten Berufen (https://ethz.ch/content/dam/ethz/special-interest/dual/kof-dam/documents/newsletter/KOF_Studie_KI_Schweizer_Arbeitsmarkt.pdf)
Forecasting Research Institute: Economic Effects of AI - 61 % moderate/rapid Progress bis 2030 (https://forecastingresearch.substack.com/p/forecasting-the-economic-effects-of-ai)
OECD: AI Paper No. 39 - GenAI-Produktivität, stark kontextabhängig (doi:10.1787/b21df222-en)
MIT Project NANDA: The GenAI Divide - State of AI in Business 2025 (https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf) - 5 % mit messbarem Wert
McKinsey: The State of AI - Global Survey 2025 (https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai) - 88 % Adoption, nur 6 % High-Performer, Workflow-Redesign stärkster EBIT-Prädiktor
RAND: The Root Causes of Failure for AI Projects (2024) (https://www.rand.org/pubs/research_reports/RRA2680-1.html) - nach Schätzungen über 80 % gescheiterte KI-Projekte
Demirci u.a.: Who Is AI Replacing? (2023) (https://ssrn.com/abstract=4602944) - Freelancer-Aufträge minus 21 %
Acemoglu: The Simple Macroeconomics of AI (NBER, 2024) (https://www.nber.org/papers/w32487) - maximal 0,66 % Produktivität über ein Jahrzehnt
Brynjolfsson u.a.: Generative AI at Work (NBER/QJE, 2025) (https://www.nber.org/papers/w31161) - plus 14 % im Kundenservice, Neulinge rund doppelt so stark
Santarelli u.a.: AI and Productivity (2025) (https://ssrn.com/abstract=5126345) - Auswertung von 371 Schätzungen, kein robuster gesamtwirtschaftlicher Effekt
Anthropic Economic Index (2026) (https://www.anthropic.com/research/anthropic-economic-index-january-2026-report); Stanford HAI: AI Index Report 2025 (https://hai.stanford.edu/ai-index/2025-ai-index-report)
Morgan Stanley; Goldman Sachs Commodities Research (2025) - US-Stromlücke, Realisierungsquote; IEA: Energy and AI (2025) (https://www.iea.org/reports/energy-and-ai); Lawrence Berkeley National Lab (2024)
Bridgewater: The Macro Implications of the AI Capex Boom (2026); Sequoia / David Cahn: AI's $600B Question (2024) (https://www.sequoiacap.com/article/ais-600b-question/); SemiAnalysis: Huawei Ascend Production Ramp (2025)
EU AI Act (Verordnung 2024/1689) (https://eur-lex.europa.eu/eli/reg/2024/1689/oj) inkl. Digital-Omnibus-Verschiebung der Hochrisiko-Fristen
Transkribierte Vorträge/Interviews (Stimmungsbild, nicht zitierfähig): Brockman, Amodei (via Dwarkesh Patel), Hossenfelder, Karpathy, Hassabis, Altman (TED), Askell, Huang (via Lex Fridman), Kurzweil (via Peter Diamandis)


